















 מאת: מיאנאק דאגה, אשווין אמ. אג’י, וו-צ’ון פנג, המכון הפוליטכני של וירג’יניה
מאת: מיאנאק דאגה, אשווין אמ. אג’י, וו-צ’ון פנג, המכון הפוליטכני של וירג’יניה
המשך לכתבה מגליון דצמבר.
תקציר – יחידות העיבוד הגרפי (GPU) התקדמו בצעדים גדולים והפכו להיות מאיצים בתחום המחשוב המקבילי. ואולם, מאחר שיחידות GPU היו עד עתה יחידות בדידות שהתחברו באמצעות אפיק PCIe, הביצועים של יישומי GPU היו נתונים תחת אפשרות של פגיעה כתוצאה מצוואר הבקבוק שנוצר בהעברת הנתונים בין יחידת העיבוד המרכזית, CPU, לבין יחידת העיבוד הגרפי, (GPU), דרך ממשק PCIe. ארכיטקטורות מחשוב הטרוגניות אשר “ממזגות” את הפונקציונליות של CPU עם זו של יחידת GPU, כמו למשל Fusion של חברת AMD או Knights Ferry של Intel, נושאות את ההבטחה למציאת פתרון לצוואר הבקבוק האמור של ממשק PCIe.

טבלה 1. פלטפורמות הבדיקה

טבלה 2. סוויטת מבחני הביצועים
במאמר זה אנו מאפיינים ומנתחים באופן ניסיוני את יעילותו של המעבד Fusion של AMD, שהוא בעל ארכיטקטורה שמשלבת באותו השבב ליבות x86 רב תכליתיות עם ליבות מאיצות הניתנות לתכנות. אנו מאפיינים את הביצועים של המעבד בעזרת מערך של מבחני ביצועים זעירים (כגון העברת נתונים דרך PCIe), מבחני ביצועים של הגרעין (kernel) (כגון פעולת חיסור) ובעזרת יישומים ממשיים (לדוגמה דינמיקה מולקולרית). בתלות במבחן הביצועים, התוצאות שלנו מראות שהמעבד Fusion מגיע לשיפור זמני העברת הנתונים המגיע לפי 1.7 עד פי 6.0 יותר בהשוואה ליחידת GPU בדידה. כתוצאה מכך, שיפור זה בביצועי העברת הנתונים יכול להגדיל באופן משמעותי את ביצועי היישום. לדוגמה, בהפעלה של מבחן ביצועים של פעולת חיסור באמצעות Fusion של AMD שבו יש 80 ליבות GPU בלבד התקבל שיפור של פי 3.5 לעומת יחידת GPU הבדידה Radeon HD 5870 של AMD שבה יש 1600 ליבות GPU בעלות יכולת רבה יותר.

איור 7. בדיקת רוחב הפס באפיק PCIe
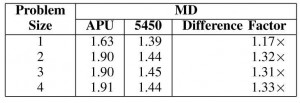
טבלה 3. ביצועי דינמיקת MD בג'יגה flop בשנייה
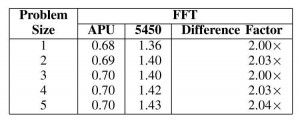
טבלה 4. הביצועים של טרנספורם FFT בג’יגה flop בשנייה
ניסויים ודיונים
בחלק זה נציג את תוצאות הניסויים שבוצעו ונערוך בהן דיון על מנת לסייע בהדגמת היעילות של מעבד שבו CPU משולב עם יחידת GPU כדוגמת יחידת APU מסוג Ontario/Zacate בסדרת G של AMD, שהיא מימוש ארכיטקטורת Fusion של AMD.
א. הקמת מערך הניסוי
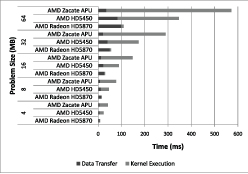
איור 8.ביצועי אפליקציה (MD ו- FFT)
טבלה 1 מספקת מידע על שלוש הפלטפורמות ששימשו לבדיקה: יחידת וגרסה עצמאית של יחידת GPU שביחידת APU, כלומר יחידת Radeon HD 5450 AMD. בחרנו את בדיקת PCIeBandwidth (בדיקת רוחב הפס של PCIe) מתוך ערכת פיתוח התוכנה Stream גרסה 2.3 של AMD וכן בארבעה מבחני ביצועים מתוך סוויטת מבחני הביצועים Scalable HeterOgeneous Computing כדי לבצע את ההערכה של פלטפורמות הבדיקה. טבלה II מספקת תיאור קצר של כל בדיקה במבחן הביצועים. הפלטפורמות תוכנתו באמצעות OpenCL גרסה 1.1 עם ערכת הפיתוח Stream גרסה 2.3 של AMD ועם מנהל ההתקן לגרפיקה Catalyst גרסה 10.7 של AMD.
ב. בדיקות רוחב הפס של אפיק PCIe
השתמשנו בבדיקת PCIeBandwidth לפי תקן OpenCL על מנת להבין את העלות הכרוכה בהעברת נתונים ביחידות GPU בדידות ובארכיטקטורת Fusion של AMD, ועל מנת לזהות מתי והיכן הביצועים של ארכיטקטורת Fusion טובים יותר. איור 7 מציג את רוחב הפס של העברת הנתונים עבור ערכי גודל נתונים משתנים בטווח שבין 1KB עד 64MB בשלוש פלטפורמות הבדיקה. (הפעלנו 10,000 פעולות חוזרות של הבדיקה עבור כל גודל של העברת נתונים).
איור 7א’ מראה את רוחבי הפס שהושגו כאשר הנתונים הועברו מיחידת “מארח” (CPU) אל יחידת ה”התקן” (יחידת GPU). על אף שיחידת APU ביטלה את הצורך בגישת PCIe, רוחב הפס שהיא השיגה עבור ערכי הגודל של נתונים קטנים יותר היה קטן יותר מזה שהושג בפלטפורמת GPU העצמאית. רק לאחר סף מסוים, הפך היתרון של ביטול אפיק PCIe ליתרון גלוי לעין, ויחידת APU התחילה להניב ביצועים טובים יותר בהשוואה לאלו של המתחרים העצמאים שלה. איור 7ב’ מציג תוצאות דומות עבור המקרה ההפוך, כלומר כאשר הנתונים מועברים מכיוון ה”התקן” (יחידת GPU) אל ה”מארח” (CPU). ואולם, עבור ההעברות “מההתקן אל המארח”, הסף שמעבר לו יחידת APU משיגה רוחב פס גדול יותר, יהיה נמוך יותר מהסף עבור העברות “מהמארח אל ההתקן”. מעבר לכך, רוחב הפס של העברות “מהמארח אל ההתקן” גבוה יותר מאשר רוחב הפס של ההעברות “מההתקן אל המארח” עבור יחידת GPU עצמאית, בשעה שההפך הוא הנכון עבור יחידת APU.
על כן האידיאולוגיה הטוענת שארכיטקטורת Fusion תתגבר על צוואר הבקבוק של אפיק PCIe הקיים בפלטפורמת GPU בדידה, איננה תמיד נכונה. רוחב הפס המושג ביחידת APU גדל עם העלייה בגודל של העברת הנתונים, עובדה שמרמזת על עלות מסוימת שקיימת בביצוע העברות נתונים, למשל הגדרת גישת DMA וריתוק מאגר זיכרון זמני (buffer pinning), ועלות זו של העברת נתונים נשחקת ככל שעולה גודל הנתונים. מהתוצאות שלנו אפשר להגיע למסקנה שיחידת APU אינה מספקת את היתרונות המובטחים של התגברות על העלויות של אפיק PCIe עבור העברות נתונים בגודל קטן, אבל היא מתחילה לממש את ההבטחה עבור גודלי נתונים גדולים יותר. בנוסף, קשה למצוא את נקודת האיזון, מאחר שהיא יכולה להשתנות מיישום ליישום (ומפני שיחידת APU מהווה במובן הרחב “תיבה שחורה” עבור משתמש הקצה שלה). ועם זאת, הבעיה הכרוכה ביצירת היקשים לגבי גודל הנתונים המהווה את הסף, היא זמנית בלבד, מפני שעל פי הצפוי, כבר בדור הבא של יחידות APU של חברת AMD ימוזגו שתי מחיצות זיכרון אלו.
ג. מבחני הביצועים של הגרעין
את היעילות של ארכיטקטורת Fusion הדגמנו באמצעות ארבעה מבחני ביצועים של יישומים (MD, טרנספורם FFT, Scan – סריקה ו-Reduction – חיסור) מתוך סוויטת מבחן הביצועים SHOC.
איור 8 ואיור 9 מציגים את זמני העברת הנתונים וביצוע הגרעין עבור כל אחד ממבחני הביצועים של היישום עם ערכי גודל משתנים של בעיה בשלוש פלטפורמות המאיצים: (1) יחידת APU של AMD, יחידת Radeon HD 5450 בדידה של AMD ו-(3) יחידת Radeon HD 5870 בדידה של AMD. (כל אחד מהמבחנים הופעל 200 פעמים והדוח מסכם את הממוצע).
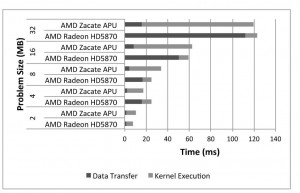
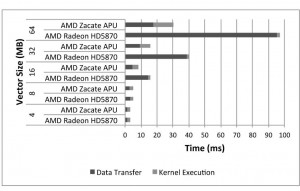
- איור 9. ביצועי אפליקציה (SCAN ו- Reduction)
מאחר שיחידת GPU הקיימת ביחידת APU זהה ליחידת Radeon HD 5450 הבדידה של AMD, אפשר היה לצפות לזמני ביצוע דומים של הגרעין בשתי פלטפורמות אלו, אך בכל זאת, לא זה היה המקרה. לא הייתה אפשרות להפעיל שני יישומים, כלומר סריקה וחיסור, ביחידת GPU הבדידה מסוג 5450 להספק נמוך בגלל הגבול העליון שקיים בה, שהוא 128 פריטי עבודה בקבוצת עבודה, בעוד שלסוויטת מבחן הביצועים HSOC נדרשים לפחות 256 פריטי עבודה כדי לפעול. לכן, לא מוצגות כאן תוצאות עבור מבחני ביצועים אלו ביחידת GPU הבדידה Radeon HD 5450 של AMD.
דינמיקה מוליקולרית (MD): באיור 8א’ מוצגים זמני העברת הנתונים וזמני ביצוע הגרעין עבור מבחן הביצועים דינמיקה מוליקולרית (MD). אפשר לראות שיחידת APU מקטינה את זמני העברת הנתונים עבור כל הגדלים הבעייתיים והיעילות של יחידת APU גדלה עם העלייה בגודל הבעיה – עובדה שתואמת למספרים של רוחב הפס שהושגו בבדיקת PCIeBandwidth לפי OpenCL המוצגות באיור 7.
 כפי שצפוי, הגרעין מתבצע במהירות הגבוהה ביותר ביחידת 5870 הבדידה של AMD בזכות קיומם של ליבות עיבוד GPU מהירות יותר באופן משמעותי ואשר מספרן גדול יותר. עם זאת, כאשר משווים את יחידת Radeon HD 5450 של AMD אל יחידת APU, ביחידת APU הגרעין התבצע באופן מפתיע מהר יותר מאשר ביחידת Radeon HD 5450.
כפי שצפוי, הגרעין מתבצע במהירות הגבוהה ביותר ביחידת 5870 הבדידה של AMD בזכות קיומם של ליבות עיבוד GPU מהירות יותר באופן משמעותי ואשר מספרן גדול יותר. עם זאת, כאשר משווים את יחידת Radeon HD 5450 של AMD אל יחידת APU, ביחידת APU הגרעין התבצע באופן מפתיע מהר יותר מאשר ביחידת Radeon HD 5450.
מתוך ניתוח פרופיל הביצוע של דינמיקת MD הסתבר שזה יישום תלוי חישובים. נמצא שתדירויות אות השעון הנוכחיות של הליבה ביחידת APU וביחידת Radeon HD 5450 של AMD היו 278 מגה הרץ ו-157 מגה הרץ בהתאמה. מכאן, שאות השעון של יחידת APU היה מהיר פי 1.77 יותר מאשר אות השעון של יחידת GPU הבדידה, ולכן גם סביר מאוד שזו היא הסיבה לביצוע המהיר יותר של הגרעין ביחידת APU. על מנת לאמת את העובדה הזו, נתוני ג’יגה flop בשנייה שהושגו עבור דינמיקת MD בשתי פלטפורמות אלו מדווחים בטבלה 3. על אף שההפרש בנתוני ג’יגה flop בשנייה שהושגו אינו פי 1.77 (ההבדל בתדירויות של אותות השעון בליבות), קיומן של ליבות עיבוד איטיות יותר ביחידת 5450 הבדידה של AMD יכול לרמז על הסיבה לביצוע האיטי יותר של הגרעין ביחידת Radeon HD 5450 של AMD.
טרנספורם פורייה מהיר (FFT): איור 8ב’ מציג את הזמנים של העברת נתונים ואת הזמנים של ביצוע הגרעין עבור טרנספורמציית FFT בממד אחד, בכל שלוש הפלטפורמות של המאיצים. בדומה למבחן הביצועים הקודם של דינמיקת MD, יחידת APU סייעה בקיצור זמני העברת הנתונים עבור טרנספורם FFT ואיפשרה את העברתם של כמות גדולה יותר של נתונים, כשהתוצאה המתקבלת היא יתרון גדול יותר ליחידת APU. כפי שצפו, זמן ביצוע הגרעין מזערי ביחידה 5870 רבת היכולת העצמאית של AMD אם משווים אותה לפלטפורמות האחרות. עם זאת, זמן ביצוע הגרעין ביחידת APU גרוע יותר מאשר ביחידת יחידת Radeon HD 5450 של AMD. היות שידוע שטרנספורמציות של טרנספורם FFT תלויות בזיכרון, הניתוח של רוחב הפס של הזיכרון של ההתקן ביחידת APU וגם זה שביחידת Radeon HD 5450 של AMD אמור לספק את הסיבה המעשית לביצוע האיטי יותר שלח הגרעין ביחידת APU.
למטרה זו חישבנו, באמצעות שימוש במבחן הביצועים שנקרא DeviceMemory של סוויטת מבחני הביצועים SHOC, את רוחב הפס הכולל של הזיכרון בשתי פלטפורמות אלו ומצאנו שרוחב הפס הכולל של הזיכרון ביחידת Radeon HD 5450 של AMD טוב פי שניים בערך יותר מאשר ביחידת APU. נוסף על כך, מדדנו את הביצועים (ג’יגה Flop בשנייה) של טרנספורם FFT בשתי הפלטפורמות, כפי שמוצג בטבלה IV. טבלה זו מראה שהביצועים שהושגו ביחידת Radeon HD 5450 של AMD טובים פי שניים מאלו שביחידת APU ומכאן אפשר להסיק שרוחב פס טוב יותר כולל לזיכרון מוביל לביצוע מהיר יותר של הגרעין ביחידת Radeon HD 5450 הבדידה של AMD.
סריקה וחיסור: איור 9א’ ואיור 9ב’ מציגים את זמני העברת הנתונים ואת זמני ביצוע הגרעין של סריקה וחיסור בהתאמה. זמן הביצוע הכולל של סריקה דומה בערך עבור יחידת GPU מסוג Radeon HD 5870 של AMD בעלת היכולת הגבוהה, ועבור יחידת APU. תוצאה ניסיונית זו מדהימה, בהינתן העובדה שליחידת Radeon HD 5870 של AMD יש לא רק ליבות GPU מהירות יותר, אלא פי עשרים יחידות כאלו בהשוואה ליחידת APU. על אף שביצוע הגרעין איטי יותר ליחידת APU, פעולות העברת הנתונים בה מהירות יותר ולכן הן מקזזות את ההשפעה של ליבות העיבוד האיטיות יותר שביחידת APU. עבור מבחן הביצועים של החיסור, זמן הביצוע הכולל בפועל היה טוב ביחידת APU בעלת “הביצועים הפחותים” יותר מאשר ביחידה Radeon HD 5870 של AMD בעלת “היכולת הטובה יותר”. הביטול של העברת נתונים דרך אפיק PCIe מאפשר ליחידות GPU המשולבות בתוך יחידת APU לספק ביצועים טובים פי שלושה יותר מאשר יחידת Radeon HD 5870 של AMD, על אף שיש להם פחות מ-1/20 מהיכולת החישובית שלה.
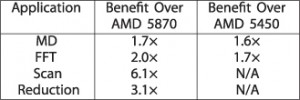
כפי שהוצג בפרק 3, ההאצה S’ היא פונקציה של התקורה המקבילית, שהיא הזמן המושקע בהעברת נתונים בין GPU ויחידת GPU, וזאת כתוצאה מהעברת יישום למקבילי ביחידת GPU שבה אינסוף ליבות עיבוד. טבלה V מסכמת את ערכי החיסכון בזמני העברת הנתונים שנגזרים מהביטול של השימוש באפיק PCIe. היתרון מחושב כיחס הקיים בין זמן העברת הנתונים בשימוש ביחידת GPU בדידה לבין זה שנמצא בשימוש ביחידת APU. עבור כל יישום, מחושב החציון של ערכי החיסכון עבור כל הגדלים הבעייתיים. ברור לעין מתוך הטבלה שארכיטקטורת Fusion של AMD מצליחה להתגבר על צוואר הבקבוק של אפיק PCIe, אשר ממנו “סובל” השימוש ביחידת GPU עצמאית.
עם זאת, עלינו לשים לב לעובדה שההאצה S’ היא גם פונקציה של p’, החלק המקבילי המואץ של התוכנית. מעבר לכך, הערך של p’ יכול להשתנות במידה משמעותית בתלות במספרן של יחידות החישוב וברוחב הפס הזמין של הזיכרון ביחידת GPU וכן גם בעוצמה החישובית (arithmetic intensity) ובתבנית הגישה לזיכרון של האלגוריתם. על אף שאפשר להקטין במידה רבה את o באמצעות שימוש בטכנולוגיית Fusion של AMD, על מנת להפחית את העלות של העברת הנתונים בין CPU לזיכרון יחידת GPU, אין כל ערבות לכך שהערך של p’ יישאר ללא שינוי בהשוואה לשימוש ביחידת GPU בדידה. עובדה זו מעוררת בעיה חשובה ומאתגרת, ומחייבת להבין את השינוי המתרחש בביצועים של p’ בין מערכת משולבת של CPU עם יחידת GPU לבין מערכת של יחידת GPU עצמאית, שזיהינו אותה וקבענו אותה לחקירה בעתיד.
עבודה קשורה
כתוצאה מהחידוש הקיים בארכיטקטורת Fusion של AMD, קשה למצוא בספרות דיונים רבים שמתייחסים לארכיטקטורה המסוימת הזו. עם זאת, נערך מחקר בהיקף משמעותי שמטרתו להעריך את הביצועים של יחידות GPU. לדוגמה, ריו (Ryoo) ועמיתים ביצעו מחקר בנוגע לאופטימיזציה והעריכו את הביצועים של יחידות GPU בדידות של חברת NVIDIA. המחברים הוכיחו שעל אף שביחידות GPU גלומה התקווה לאספקת יתרונות משמעותיים, יש צורך להתמיד בביצוע אופטימיזציה של יישומי GPU. יאנג (Jang) ועמיתים וז’ודונג (Xudong) ועמיתים, אשר הציעו אסטרטגיות לביצוע אופטימיזציה של יחידות GPU של AMD באמצעות שפת התכנות Brook+ והעריכו אותן על מימוש של גרעין כפל מטריצות ושל יישום מרובה סריגים (multi grid) לפתרון של משוואות דיפרנציאליות חלקיות (PDE) בהתאמה.
מסקנות ועבודה עתידית
הוכח שיחידות GPU מספקות יתרון גדול למדי בהאצה של יישומים מדעיים רבים. עם זאת, הביצועים של יישומים עם יחידות GPU נפגעים לעתים קרובות מפעולות ההעברה האיטיות בין CPU ליחידת GPU המבוצעות באפיק PCIe. ארכיטקטורות חדשניות, כדוגמת Fusion של AMD, אשר מבטלות את הצורך בגישה אל יחידת GPU וממנה דרך אפיק PCIe, נושאות את ההבטחה שהן יצליחו להתגבר על צווארי בקבוק אלו ומכאן לשפר את הביצועים של היישומים.
במאמר זה הדגמנו באופן ניסויי את היעילות של ארכיטקטורת Fusion כאשר העלויות של העברת הנתונים דרך אפיק PCIe מוחלפות בפעולות העברה פשוטות ומהירות של בלוקים של זיכרון בין מחיצות הזיכרון של x86 ושל מנועי SIMD. הראינו שביישומים מסוימים, אפשר להקטין את העלויות האלה, עד כדי פי שישה. עם זאת, במקרים של העברת נתונים בערכי גודל קטנים יותר, מצאנו שהעלות של העברת הנתונים בארכיטקטורת Fusion של AMD הייתה גרועה יותר מאשר המתחרה העצמאית שלה. בעיה זו מצביעה כנראה על האפשרות הסבירה, לפיה מנגנוני פרוטוקולים ומדיניות הנמצאים ביסוד הפעולות, אשר להם יש עלות גבוהה, הם שיוצרים עלויות של תקורה, שאותן אין אפשרות להקטין, אלא כאשר מגיעים לסף של העברת נתונים בגודל מסוים. צפוי שבארכיטקטורות עתידיות של יחידות APU ימוזגו מחיצות הזיכרון האלו באופן חלק, והמשמעות היא שלא יהיה צורך בהעברת נתונים כלל אל זיכרון יחידת GPU וממנו, ושהביצועים הכוללים של היישום רק ישתפרו.
לבסוף, הראינו שביצועי היישומים בארכיטקטורת Fusion של AMD עמידים מאוד. באופן מיוחד, עבור מבחן ביצועים מסוים, למשל עבור חיסור, שבו ארכיטקטורת Fusion סיפקה שיפור של פי שלושה בביצועי היישום, בהשוואה לשימוש ביחידת GPU בדידה, שלה יש יכולת חישובית פי 20 גדולה יותר.
הכתבה באדיבות אתר: http://synergy.cs.vt.edu/publications.php


