















בשעה שיחידות עיבוד גראפי לשימוש כללי (general-purpose graphics processing units – GP-GPUs) מציעות קצבים גבוהים של פעולות בשנייה בשיא נקודה צפה (floating-point operations per , מציעים עתה רמות תחרותיות של עיבוד בנקודה צפה. יתר על כן, ה-®FPGAs של Altera תומכים עתה ב-™OpenCL, שפת תכנות מובילה המשמשת ב-™GPUs.
מבוא
FPGAs ו-CPUs היוו במשך זמן רב חלק אינטגראלי של עיבוד אותות מכ”מיים. FPGAs משמשים לרוב עבור עיבוד בחזית (front end), בעוד ה-CPUs עבור העיבוד בעורף (back-end). בשעה שמערכות מכ”ם גדלות ביכולת ובמורכבות, דרישות העיבוד גברו בצורה דרמטית. בעוד ה-FPGAs שמרו על יכולות העיבוד והתפוקה הגדלות, CPUs נאבקו לספק את ביצועי עיבוד האותות הדרושים במכ”ם של הדור הבא. מאבק זה הוביל לשימוש גובר במאיצי CPU, דוגמת יחידות עיבוד גראפי (GPUs), כדי לתמוך בעומסי העיבוד הכבדים.
דו”ח מוסמך (white paper) זה משווה בין ביצועים ותזרימי התכנון בנקודה צפה של FPGAs ו-GPUs. בשנים האחרונות, GPUs נעו אל פלטפורמות עיבוד בנקודה צפה חזקות (הידועות כ-GP-GPUs), המציעות קצבים גבוהים של FLOPs בשיא. FPGAs, אשר שימשו בעבר בעיקר לעיבוד אותות דיגיטלי בנקודה קבועה (digital signal processing – DSP), מציעים עתה רמות תחרותיות של עיבוד בנקודה צפה, ההופכות אותם למועמדים להאצת עיבוד מכ”ם עורפי.
בחזית ה-FPGA, מספר מידודים (benchmarks) בנקודה צפה שניתנים לבחינה פורסמו הן ב-40 ננו-מטר והן ב-28 ננו-מטר. ה-FPGAs בעלי הביצועים הגבוהים מהדור הבא של Altera יתמכו בלפחות 5TFLOPs של ביצועים על-ידי מינוף של תהליך ה-14 ננו-מטר Tri-Gate של Intel. ניתן לצפות לעד 100 GFLOPs/W תוך שימוש בתהליך מוליכים-למחצה מתקדם זה. יתר על כן, ה-FPGAs של Altera תומכים עתה ב-OpenCL, שפת תכנות מובילה המשמשת עם ה-GPUs.
דירוגי GFLOPs בשיא
ל-FPGAs המקובלים יש יכולות של 1+peak , בעוד ה-GPUs החדשים ביותר של AMD ו-Nvidia מדורגים אף גבוה יותר, עד לקרוב ל-4TFLOPs. אולם, ה-GFLOPs או ה-TFLOPs בשיא מספקים מידע מועט על הביצועים של התקן נתון ביישום מסוים. הוא מצביע בעיקר על המספר הכולל של חיבורים או מכפלות בנקודה צפה שניתן לבצע בשנייה. ניתוח זה מראה שה-FPGAs יכולים, במקרים רבים, לעלות על התפוקה של ה-GPUs באלגוריתמים וממדי נתונים המקובלים ביישומי מכ”ם.
אלגוריתם מקובל בעל מורכבות בינונית הוא ה-fast Fourier transform (). מאחר שרוב מערכות המכ”ם מבצעות הרבה מהעיבודים שלהן במישור התדר, אלגוריתם ה-FFT מתפקד בצורה מאוד כבדה. לדוגמה, FFT בעל 4,096 נקודות מומש תוך שימוש בעיבוד נקודה צפה בעל דיוק יחיד (single-precision). הוא יכול להכניס ולהוציא ארבע דגימות מרוכבות למחזור שעון. כל ליבת FFT יחידה יכולה לפעול במעל 80GFLOPs ול-FPGA גדול בעל 28 ננו-מטר יש משאבים לממש שבע ליבות כאלה.
אולם, כמוצג באיור 1, אלגוריתם ה-FFT על FPGA זה הוא קרוב ל-400GFLOPs. תוצאה זו מבוססת על הידור OpenCL בעל “לחצן”, ללא צורך במומחיות ב-FPGA. תוך שימוש בייטובי logic-lock ו-Design Space Explorer (), תכנון שבע הליבות יכול להתקרב ל-fMAX של תכנון בעל ליבה אחת, המעלה אותו עד מעל 500GFLOPs עם מעל 10GFLOPs/W תוך שימוש ב-FPGAs של 28 ננו-מטר.
תוצאת GFLOPs/W זו היא הרבה יותר גבוהה מאשר יעילות ההספק CPU או GPU שניתן להשיג. במונחים של השוואות GPU, ה-GPU איננו יעיל באורכי FFT אלה, כך שלא מוצגים כל מידודים. ה-GPU הופך ליעיל עם אורכי FFT של כמה מאות אלפי נקודות, כאשר הוא יכול לספק האצה שימושית עבור CPU. אולם, אורכי ה-FFT הקצרים יותר נפוצים בעיבוד מכ”מי, בו אורכי FFT של 512 עד 8,192 הם הנורמה.
בסיכום, ה-GFLOPs השימושיים הם לעתים קרובות חלק מה-GFLOPs שבשיא או התיאורטיים. מסיבה זו, גישה טובה יותר היא להשוות ביצועים עם אלגוריתם שיכול להציג בצורה סבירה את המאפיינים של יישומים טיפוסיים. ככל שמורכבות אלגוריתם המידוד עולה, הוא הופך ליותר מייצג את ביצועי מערכת מכ”ם מעשית.
מידוד האלגוריתם
במקום לסמוך על הערכות המשווק על GFLOPs בשיא כדי להזין את החלטות טכנולוגיית העיבוד, קיימת חלופה של לסמוך על הערכות גוף שלישי תוך שימוש בדוגמאות בעלות מורכבות מספקת. אלגוריתם נפוץ עבור מכ”ם בעל עיבוד תואם מקום-זמן (space-time adaptive processing – STAP) הוא הפירוק (decomposition) של Cholesky. אלגוריתם זה משמש לעתים קרובות באלגברה ליניארית לשם פיתרון יעיל של משוואות מרובות, ויכול לשמש במטריצות מיתאם (correlation).
לאלגוריתם של Cholesky מורכבות מספרית גבוהה והוא דורש כמעט תמיד תצוגה מספרית בנקודה צפה לשם תוצאות סבירות. החישובים הדרושים הם יחסיים ל-N3, כאשר N הוא ממד המטריצה, כך שדרישות העיבוד הן לעתים תובעניות. מאחר שמערכות מכ”ם פועלות לרוב בזמן ממשי, דרושה תפוקה גבוהה. התוצאה תהיה תלויה הן בממדי המטריצה והן בתפוקת עיבוד המטריצה הדרושה, אך היא יכולה להיות לעתים קרובות מעל 100GFLOPs.
טבלה 1 מראה תוצאות מידוד המבוססות על GPU של Nvidia המדורג ב-1.35TFLOPs, תוך שימוש בספריות שונות, כמו גם Xilinx Virtex6 Xc6VSX475T, FPGA המיוטב עבור עיבוד DSP עם צפיפות של 475K LCs. התקנים אלה דומים בצפיפות ל-FPGA של Altera אשר שימש במידוד Cholesky. ה-LAPACK וה-MAGMA הן ספריות מסופקות מסחרית, בשעה שה-GFLOPs של ה-GPU מתייחס למימוש ה-OpenCL אשר פותח באוניברסיטת (2). האחרון הוא בבירור יותר מיוטב בממדי מטריצה קטנים יותר.
®FPGA Stratix V Altera בעל ממדים בינוניים (460K אלמנטים לוגיים – logic elements – LEs) מודד על-ידי Altera תוך שימוש באלגוריתם Cholesky בעיבוד בנקודה צפה בעל דיוק יחיד. כמתואר בטבלה 2, ביצועי ה-FPGA Stratix V על אלגוריתם Cholesky הם הרבה יותר גבוהים מאשר תוצאות Xilinx. מידודי Altera כוללים גם פירוק QR, אלגוריתם לעיבוד מטריצות אחר בעל מורכבות סבירה. שניהם, ה-Cholesky וה-QRD זמינים בתור ליבות שניתן להפוך לפרמטרים מ-Altera.
יש לציין שממדי המטריצות של המידודים אינם זהים. תוצאות האוניברסיטה של Tennessee מתחילות בממדי מטריצות של [512×512], בשעה שמידודי Altera מגיעים עד [360×360] עבור Cholesky ו-[450×450] עבור QRD. הסיבה היא ש-GPUs הם מאוד לא יעילים בממדי מטריצות קטנים יותר, כך שהתמריץ להשתמש בהם כדי להאיץ CPU במקרים אלה הוא מאוד קטן. לעומת זאת, FPGAs יכולים לפעול ביעילות עם מטריצות הרבה יותר קטנות. יעילות זו היא קריטית, מאחר שמערכות מכ”ם דורשות תפוקה יחסית גבוהה, בסדרי גודל של אלפי מטריצות בשנייה. כך שמשתמשים בממדים קטנים יותר, אף כאשר הדבר דורש להמיר מטריצה גדולה יותר לקטנות יותר לשם עיבוד.
בנוסף, מידודי Altera הם לפי ליבת Cholesky יחידה. כל ליבת Cholesky הניתנת להפיכה לפרמטרים מאפשרת בחירה של ממדי המטריצה, ממדי הווקטור ומניית הערוצים. ממדי הווקטור קובעים בגדול את משאבי ה-FPGA. ממדי המטריצה הגדולים יותר [360×360] משתמשים בממד ווקטור גדול יותר, המאפשר ליבה יחידה ב-FPGA זה, ב-91GFLOPs. המטריצה הקטנה יותר [60×60] משתמשת בפחות משאבים, כך שניתן לממש שתי ליבות, עבור סה”כ של 2×42=84GFLOPs. הגודל הקטן ביותר של מטריצה [30×30] מאפשר שלוש ליבות, עבור סה”כ של 3×25=75GFLOPs.
FPGAs נראים הרבה יותר מתאימים לבעיות בעלות ממדי נתונים קטנים, כמו המקרה של מערכות מכ”ם רבות. היעילות המופחתת של ה-GPUs נובעת מעומסי מחשוב הגדלים כ- ,I/O של נתונים הגדלים כ-N2, ולפעמים צווארי-הבקבוק של I/O של ה-GPU הופכים לבעיה פחותה ככל שמערך הנתונים גדל. בנוסף, כאשר ממדי המטריצה גדלים, תפוקת המטריצה לשנייה נופלת דרמטית בשל העיבוד הגובר למטריצה. בנקודה מסוימת, התפוקה נהית נמוכה מידי והיא הופכת לבלתי שמישה עבור הדרישות בזמן אמת של מערכות מכ”ם.
עבור FFTs, עומס המחשוב עולה ל-N log2N, בשעה ש-I/O הנתונים גדל כ-N. שוב, בממדי נתונים גדולים מאוד, ה-GPU הופך למכונת מחשוב יעילה. בניגוד לכך, ה-FPGA היא מכונת מחשוב יעילה בכל ממדי הנתונים, ומתאימה יותר ברוב יישומי המכ”ם כאשר ממדי ה-FFT הם צנועים, אך התפוקה היא בעלת עדיפות ראשונה.
מתודולוגיית תכנון של GPU ו-FPGA
GPUs מתוכננים תוך שימוש הן בשפת CUDA השייכת ל-Nvidia, והן בשפת OpenCL בעלת התקן הפתוח. שפות אלה דומות מאוד ביכולת, כאשר ההבדל הגדול הוא שה-CUDA יכולה לשמש רק ב-GPUs של Nvidia.
FPGAs מתוכנתים אופיינית תוך שימוש בשפות HDL Verilog או VHDL. אף אחת משפות אלו איננה מתאימה היטב לתמיכה בתכנוני נקודה צפה, אם כי הגרסאות האחרונות כוללות הגדרה, לאו דווקא סינתזה, של מספרי נקודה צפה. לדוגמה, ב-System Verilog, משתנה ממשי קצר הוא אנלוגי ל-IEEE יחיד (צף), וממשי ל-IEEE כפול.
ערכת גוש (blockset) מתקדמת עבור בונה ה-DSP
סינתזה של נתיבי נתונים (datapaths) בעלי נקודה צפה אל FPGA תוך שימוש בשיטות מקובלות היא מאוד לא יעילה, כמוצג על-ידי הביצועים הנמוכים של FPGAs של Xilinx על אלגוריתם Cholesky, הממומש תוך שימוש בפונקציות Xilinx Floating-Point Core Gen. אולם, Altera מציעה שתי חלופות. הראשונה היא להשתמש ב-DSP Builder Advanced Blockset, פריט תכנון מבוסס על Mathworks. כלי זה כולל תמיכה עבור מספרים הן בנקודה קבועה והן בנקודה צפה, ותומך בשבעה דיוקים שונים של עיבוד בנקודה צפה, כולל מימושים ב-IEEE מחצית-, יחיד-, ובעל דיוק כפול. הוא תומך גם בווקטוריזציה, הדרושה לשם מימוש יעיל של אלגברה ליניארית. הדבר החשוב ביותר הוא היכולת למפות מעגלי נקודה צפה ביעילות לתוך ארכיטקטורות FPGA בעלות נקודה קבועה של היום, כמוכח על-ידי המידוד התומך בקרוב ל-100GFLOPs על אלגוריתם Cholesky ב-FPGA בעל ממדים בינוניים של 28 ננו-מטר. לשם השוואה, מימוש Cholesky ב-FPGA של Xilinx בעל ממדים דומים ללא יכולת הסינתוז הזאת מראה רק 20GFLOPs של ביצועים על אותו האלגוריתם (2).
OpenCL עבור FPGAs
OpenCL מוכרת לתכנתי ה-GPU. מהדר (3)OpenCL עבור FPGAs פירושו שקוד OpenCL הנכתב עבור GPUs של AMD או Nvidia ניתן להדר לתוך FPGA. בנוסף, מהדר OpenCL של Altera מאפשר לתכניות GPU להשתמש ב-FPGAs, ללא הצורך לפתח את ערכת הגוש לתכנון FPGA האופיינית.
השימוש ב-OpenCL עם FPGAs מציע יתרונות-מפתח אחדים לעומת ה-GPUs. ראשית, GPUs נוטים להיות מוגבלים ב-I/O. חייבים להעביר את כל נתוני המבוא והמוצא על-ידי ה-CPU המארח דרך ממשק
ה-®PCI Express (). ההשהיות הנגרמות יכולות לעכב את מנגנוני העיבוד של ה-GPU, ולגרום לביצועים נמוכים יותר.
הרחבות OpenCL עבור FPGAs
FPGAs ידועים היטב בגין המגוון הרחב של יכולות ה-I/O בעלות רוחב-פס גבוה. יכולות אלו מאפשרות לנתונים לזרום אל- ומה-FPGA דרך Gigabit
®Ethernet (GbE), Serial RapidIO
() או ישירות מממירים אנלוגי לדיגיטלי (ADCs) וממירים דיגיטלי לאנלוגי (DACs). הגדירה הרחבה מיוחדת למפיץ של התקן OpenCL אשר תתמוך בזרימת הפעולות. הרחבה זו היא תכונה קריטית במערכות מכ”ם, מאחר שהיא מאפשרת לנתונים לנוע ישירות מיצירת האלומה בנקודה קבועה בחזית והעיבוד מפחית ההמרה הדיגיטלית אל שלבי העיבוד בנקודה צפה עבור דחיסת פולסים, Doppler, STAP, מערכת דיווח/חיווי מיקום מטרה נעה (moving target indicator – MTI) ופונקציות אחרות המוצגות באיור 2. בדרך זו, תזרים הנתונים מונע את צוואר-הבקבוק של ה-CPU לפני העברתו למאיץ GPU, כך שהכמיסות הכוללת של העיבוד מוקטנת.
FPGAs יכולים גם להציע כמיסות עיבוד הרבה יותר נמוכה מאשר GPU, אף בלתי-תלויה בצווארי-הבקבוק של ה-I/O. ידוע היטב ש-GPUs חייבים לפעול על הרבה אלפי הליכים (threads) כדי לתפקד ביעילות, בשל הכמיסויות הארוכות מאוד מהזיכרון ואליו ואף בין ליבות התהליך הרבות של ה-GPU. למעשה, ה-GPU חייב להפעיל משימות רבות ביותר כדי לשמור על ליבות התהליך מלעצור בשעה שהן מחכות לנתונים, דבר הגורם לכמיסות מאוד ארוכה עבור כל משימה נתונה.
ה-FPGA משתמש במקום זאת בארכיטקטורת “מקבילות בעלת גרעון גס” (coarse-grained parallelism). היא יוצרת נתיבי נתונים מיוטבים ומקבילים, כאשר כל אחד מהם מפיק תוצאה אחת למחזור שעון אחד. מספר הדוגמאות של נתיב הנתונים תלוי במשאבי ה-FPGA, אך הוא אופיינית הרבה יותר קטן מאשר מספר ליבות ה-GPU. אולם, לכל דוגמה של נתיב הנתונים יש תפוקה הרבה יותר גבוהה מאשר ליבת GPU. היתרון העיקרי של גישה זו הוא כמיסות נמוכה, יתרון בעל ביצוע קריטי ביישומים רבים.
יתרון נוסף של ה-FPGAs הוא תצרוכת ההספק הנמוכה הרבה יותר שלהם, הגורמת ל-GFLOPs/W דרמטית נמוכים יותר. מדידות הספק של FPGA תוך שימוש בכרטיסי פיתוח מראות 5-6GFLOPs/W עבור אלגוריתמים כגון Cholesky ו-QRD, וכ-10GFLOPs/W עבור אלגוריתמים פשוטים יותר דוגמת ה-FFTs. מדידות יעילות האנרגיה ב-GPU הרבה יותר קשה למצוא, אך שימוש בביצועי ה-GPU של 50GFLOPs עבור Cholesky וצריכת הספק אופיינית של 200 ואט, גורם ל-0.25GFLOPs/W, שהוא עשרים מונים יותר הספק נצרך ל-FLOPs שימושיים.
עבור מכ”ם מוטס או מותקן על רכב, גודל, שיקולי משקל והספק (size, weight and power – SWaP) הם מכריעים. ניתן לתאר בקלות מזל”ט נושא מכ”ם עם עשרות TFLOPs במערכות עתידיות. כמות הספק העיבוד הזמין קשורה לרזולוציה ולכיסוי המותרים של מערכת מכ”ם חדשנית.
נתיב נתונים מאוחד (fused)
שני יצרני ה-OpenCL וה-DSP מסתמכים על טכניקה ידועה כ”נתיב נתונים מאוחד” (fused datapath) (איור 3), כאשר עיבוד הנקודה הצפה ממומש כך שיקטין משמעותית את מספר מעגלי הזזת החבית (“barrel-shifting”) הדרושים, המאפשר בעצמו לבנות תכנוני נקודה צפה בקנה-מידה גדול וביצועים גבוהים תוך שימוש ב-FPGAs.
כדי להקטין את תדירות המימוש של הזזת חבית, תהליך הסנתוז מחפש הזדמנויות בהן שימוש ברוחבי מנטיסה גדולים יותר יכולים לנטרל את הצורך בנרמול ואי-נרמול תכופים. הזמינות של מכפילים קשוחים 27×27 ו-36×36 מאפשרת מכפילים משמעותית גדולים יותר מאשר ה-23 ביטים הדרושים על-ידי מימושים של דיוק-יחיד, וכ”כ הבנייה של מכפילי 54×54 ו-72×72 מאפשרת יותר מאשר 52 הביטים הדרושים עבור מימושים בעלי דיוק כפול. הלוגיקה של FPGA מיוטבת כבר עבור מימוש של מעגלי חיבור גדולים, בנקודה צפה, הכוללים מעגלים מובנים carry look-ahead.
כאשר דרוש נרמול ואי-נרמול, מימוש חלופי המונע ביצועים נמוכים וניתוב מופרז הוא להשתמש במכפילים. עבור מנטיסה -24ביט בעלת דיוק יחיד (כולל ביט הסימן), המכפיל 24×24 מזיז את המבוא על-ידי הכפלה ב-2n. שוב, הזמינות של מכפילים מוקשחים ב-27×27 ו-36×36 מאפשרת ממדי מנטיסה מוגדלים במימושים בעלי דיוק יחיד, ויכולה לשמש לבניית ממדי המכפיל עבור מימושי דיוק כפול.
מכפלת נקודת וקטור היא הפעולה המודגשת הצורכת את עיקר ה-FLOPs המשמשים באלגוריתמי אלגברה ליניארית רבים. מימוש של דיוק יחיד של מכפלה באורך 64 ידרוש 64 מכפילי נקודה צפה, ובהמשך עץ חיבור המורכב מ-63 מחברים בעלי נקודה צפה. מימוש כזה ידרוש הרבה מעגלי הזזת חבית.
במקום זאת, המוצאים של 64 המכפילים ניתנים לאי-נרמול אל מעריך משותף, שהוא הגדול מבין 64 המעריכים. אח”כ ניתן לחבר את 4 מוצאים אלה תוך שימוש במעגל חיבור בעל נקודה קבועה, ונרמול סופי יבוצע בסיום עץ החיבור. עיבוד נקודה צפה בעל גוש מוגבל במקום (localized-block) חוסך את כל הנרמול ואי-הנרמול-ביניים הדרושים בכל מחבר יחיד, והוא מוצג באיור 4. אפילו עם עיבוד נקודה צפה IEEE 754, המספר בעל המעריך הגדול ביותר קובע את המעריך בסוף, כך ששינוי זה רק מעביר את כיוון המעריך לנקודה מוקדמת יותר בחישוב.
אולם, כאשר מבצעים עיבוד אותות, התוצאות הטובות ביותר מושגות על-ידי שימוש בדיוק הרב ביותר האפשרי כדי לבצע קטימה (truncation) של תוצאות בסוף החישוב. הגישה כאן מפצה על אי-נרמול תת-ייטובי מוקדם זה על-ידי העברה של רוחבי ביט מנטיסה נוספים מעל הדרוש על-ידי עיבוד נקודה צפה בעל דיוק יחיד, לרוב מ-27 ל-36 ביטים. הרחבת המנטיסה מבוצעת בעזרת מכפילי נקודה צפה כדי לבטל את הצורך בנרמול המכפלה בכל שלב.
גישה זו יכולה גם ליצור תוצאה אחת למחזור שעון. ארכיטקטורות GPU יכולות ליצור את כל מכפילי הנקודה הצפה במקביל, אך הן אינן יכולות לבצע ביעילות את החיבורים במקביל. אי-יכולת זו היא בשל דרישות המכתיבות שליבות שונות חייבות להעביר נתונים דרך זכרונות מקומיים כדי לתקשר זו עם זו, ולכן הם חסרים את היכולת של קישוריות של ארכיטקטורת FPGA.
גישת נתיב הנתונים המאוחד יוצרת תוצאות שהן יותר מדויקות מאשר תוצאות נקודה צפה IEEE 754 מקובלות, כמתואר בטבלה 3.
תוצאות אלו הושגו על-ידי מימוש של הפיכות מטריצות גדולות תוך שימוש באלגוריתם הפירוק של Cholesky. אותו האלגוריתם מומש בשלוש דרכים שונות:
ב-MATLAB/Simulink עם עיבוד נקודה צפה IEEE 754 בעלת דיוק יחיד.
בעיבוד RTL עם עיבוד נקודה צפה בעלת דיוק יחיד תוך שימוש בגישת נתיב הנתונים המאוחד.
ב-MATLAB עם עיבוד נקודה צפה בעלת דיוק כפול.
מימוש בעל דיוק כפול הוא בערך מיליארד פעמים (109) יותר מדויק מאשר מימוש בעל דיוק יחיד.
השוואה זו של שגיאות MATLAB בעלות דיוק יחיד, שגיאות RTL בעלות דיוק יחיד ו-שגיאות בעלות דיוק כפול של MATLAB מאשרת את שלמות גישת נתיב הנתונים המאוחד. גישה זו מוצגת הן עבור השגיאה המנורמלת לעבר כל המרכיבים המרוכבים במטריצת המוצא והן עבור אלמנט המטריצה בעל השגיאה המרבית. השגיאה הכוללת או norm מחושבת תוך שימוש בנורם של Frobius:
>מאחר שהנורם כולל שגיאות בכל המרכיבים, הוא לעתים קרובות הרבה יותר גדול מאשר השגיאות הפרטניות.
בנוסף, תזרימי הכלים של שני ה-DSP Builder Advanced Blockset וה-OpenCL תומכים בשקיפות ומייטבים תכנונים שוטפים עבור ארכיטקטורות FPGA עתידיות. ניתן לצפות לעד 100peak GFLOPs/W, בשל הן החידושים הארכיטקטוניים והן החידושים בטכנולוגיית התהליכים.
סיכום
למערכות מכ”ם בעלות ביצועים גבוהים יש כעת אופציות פלטפורמות עיבוד חדשות. בנוסף ל-SWaP משופר מאוד, FPGAs יכולים לספק כמיסות נמוכה יותר ו-GFLOPs גבוהים יותר מאשר פתרונות מבוססי-מעבדים. יתרונות אלה יהיו אף יותר דרמטיים עם השקת FPGAs מהדור הבא, בעלי ביצועים גבוהים ומיוטבי-מחשוב.
המהדר OpenCL של החברה מספק נתיב כמעט ללא תפר עבור תכנתי GPU לשם הערכת היתרונות של ארכיטקטורת עיבוד חדשה זו. ה-OpenCL של החברה תואמת 1.2, עם מערך מלא של תמיכת ספריית מתמטיקה. היא מבטלת לחלוטין את אתגרי ה-FPGA המקובלים של סגירת תזמון, ניהול זיכרון DDR וממשוק מעבד מארח PCIe.
עבור לקוחות שאינם מפתחים GPU, החברה מציעה תזרים כלים DSP Builder Advanced Blockset, המאפשר למפתחים לבנות תכנוני DSP בעלי fMAX גבוה בנקודה קבועה או צפה, תוך שמירת היתרונות של סביבת הדמיה ופיתוח מבוססת – Mathworks. מוצר זה היה בשימוש במשך שנים על-ידי מפתחי מכ”ם תוך שימוש ב-FPGAs כדי לאפשר זרימת עבודה והדמיה יותר יצרניים, המציעים אותם ביצועי fMAX כמו HDL מקודד ידנית.
מידע נוסף
1.White Paper: Achieving One TeraFLOPS with 28-nm FPGAs
www.altera.com/literature/wp/wp-01142-teraflops.pdf
2. Performance Comparison of Cholesky Decomposition on GPUs and FPGAs, Depeng Yang, Junqing Sun, JunKu Lee, Getao Liang, David D. Jenkins, Gregory D
Peterson, and Husheng Li, Department of Electrical Engineering and Computer
Science, University of Tennessee:
saahpc.ncsa.illinois.edu/10/papers/paper_45.pdf
3. White Paper: Implementing FPGA Design with the OpenCL Standard
www.altera.com/literature/wp/wp-01173-opencl.pdf
הבעת תודה
Michael Parker, DSP Product Planning Manager, Altera Corporation *
הכתבה נמסרה באדיבות חברת איסטרוניקס
-
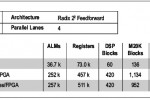
- איור 1. ביצועי Stratix V 5SGSD8 FPGA Floating Point FFT
-
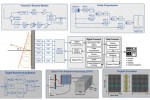
- איור 2. דיאגרמה גנרית של עיבוד אותות מכ”ם
-
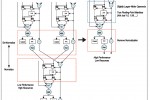
- איור 3. מימוש נתיב נתונים מאוחד של עיבוד בנקודה צפה
-
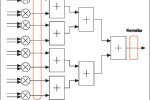
- איור 4. ייטוב של Vector Dot Product
-
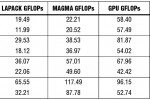
- טבלה 1. מידוד (2) Cholesky FPGA GPU ו-Xilinx
-
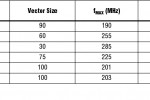
- טבלה 2. מידודי FPGA Cholesky ו-QR של Altera
-
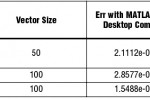
- טבלה 3. דיוק פירוק Cholesky (דיוק יחיד)
