




מחוות אנושיות הן חלק בלתי נפרד בתקשורת טבעית בין בני אדם ומשמשות להשלמת הביטוי המילולי אותו נרצה להעביר. מחוות אלה כוללות תנועות ידיים, הבעות פנים, תנוחת גוף, והנעת ראש, וכל אלו מסייעים להעביר רגשות, כוונות ורמזים נוספים שאינם נאמרים במילים. יכולת הקריאה והבנה של מחוות אנושיות מהווה חלק מרכזי בתקשורת האפקטיבית בין בני אדם.
במהלך השנים עולם הרובוטיקה התפתח משמעותית כתוצאה מהתפתחות עולמות הבינה המלאכותית (AI). היכולת של המשתמש כיום לשלוט על הרובוט ולהסתייע בו במשימות יום יומיות השתפר בצורה דרסטית. את היכולת הזאת ניתן למנף למשימות בתחומי התעשייה, רפואה, חילוץ והצלה ואפילו משימות ביתיות. היכולת של האדם לתקשר עם הרובוט בצורה טבעית כמו שיחה או הדרכה בין בני אדם היא נדבך חשוב בעולם של אינטראקציה בין אדם לרובוט (HRI). אינטראקציה זו מתארת את האופן בו בני אדם והרובוטים מתקשרים, משתפים פעולה ופועלים זה לצד זה. תקשורת טבעית הינה אחת מסוגי האינטראקציות בין אדם לרובוט, בתקשורת זו נרצה לייצר היתכנות של הדרכה אנושית לצורך העברת המסר לרובוט וניווטו למיקום הרצוי.

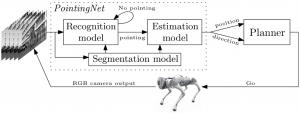
איור1: המשתמש מכווין את רובוט למיקום הרצוי על ידי הצבעה. הרובוט צופה במשתמש ומזהה את המחווה ומעריך את המיקום והכיוון של היעד הרצוי. לאחר זיהוי המטרה, הרובוט מתכנן תנועה ונע לכיוון המטרה.
אחת מסוגי המחוות הנפוצות בתקשורת טבעית היא הצבעה, היא מחווה אוניברסלית בה האדם מושיט את הזרוע והאצבע מורה לכיוון המטרה הרצויה. ניתן להיעזר במחוות כמו כדי להתמודדות עם מחסום השפה. בעזרת הצבעה ניתן להעביר מידע חיוני לגבי נקודת עניין כלשהי בסביבה. המשתמש יוכל לתקשר בקלות עם הרובוט ולהכווין אותו למיקום הרצוי ובכך הרובוט יוכל לסייע למשתמש במשימות. כפי שניתן לראות באיור 1, המשתמש מצביעה לנקודה מסוימת, הרובוט מזהה את ההצבעה ומשערך את הזווית ובכך המשתמש מכווין את הרובוט לנקודה הרצויה. כדי שהרובוט יוכל לסייע למשתמש עליו לזהות את המחווה ולכן

איור 2: איסוף נתונים (a) עבור מודל זיהוי על ידי תיוג תמונות עם הצבעה (שמאלי) או אי הצבעה (ימין), וכן (b) תיוג תמונות עם מרקרים ומערכת לכידת תמונה המזהה את הסמן היושב על האצבע ביחס לסמן של המצלמה.
נדרש שלרובוט תהיה מערכת מצלמות שתספק את היכולת של ראייה. מרבית המערכות כיום מבוססות על מצלמות עומק, כתוצאה מכך מרבית הגישות העדכניות לזיהוי מחוות או שערוכם מבוססות על מצלמות מסוג זה. אך עם זאת, מצלמות עומק מוגבלות לסביבות ביתיות ומספקות תהליך חיזוי מוגבל, מכיוון שהיכולת שלהם ללכוד פרטים כאשר האובייקט רחוק מהמצלמה היא דלה. בנוסף, מצלמות עומק יקרות ועלותם מייקרת את המערכת הכוללת. בחינה של מצלמות אינטרנט לצורך המשימה הוכחה כמוצלחת, לא רק בסביבה ביתית אלה גם בסביבות חיצוניות אשר רוויות מפריעים ברקע או כאשר האובייקט נמצא רחוק מהמצלמה.
במחקר הנוכחי אנו שואפים שרובוטים ניידים יזההו מחווה מסוג הצבעה ויגיעו למיקום הרצוי. לשם כך, פיתחנו טכניקה מיוחדת המבוססת על מידע של תמונות המצליחה לזהות הצבעה ולשערך את מיקומה והזווית שלה. המסגרת שלנו כוללת מספר מודלים אשר אחראים על סיווג בינארי, שיערוך פרמטרים (רגרסיה) ופילוח של תמונה (סגמנטציה). לצורך אימון המודלים נדרש לאסוף מידע המבוסס על תמונות בשתי תצורות, כפי שניתן לראות באיור 2 בתצורה הראשונה לצורך אימון מודל מסווג נדרש לרכוש מידע מתיוג של תמונות הכוללות הצבעה או אי הצבעה. בתצורה השנייה נאסוף את המידע בעזרת מרקרים הממוקמים על האצבע של המשתמש ועל המצלמה כך שהמערכת מצלמות אשר לוכדות תנועה יזהו את המרקרים ובכך נוכל לתייג את המידע שנרכש אשר יכלול תמונה, מיקום הצבעה ואת כיוונה בעזרת הזוויות עלרוד (Pitch) ו-סבסוב (Yaw). המידע של המודל זיהוי נרכש בסביבות מגוונות, בתוך מבנים ובחוץ עם רקעים שונים ומגוון משתמשים. לעומת זאת, כתוצאה מאילוצי מערכת המידע של המודל המשערך נרכש במעבדה בלבד עם מספר רב של משתמשים. יתרה מכך, תהליך רכישת התמונות נעשתה בעזרת מצלמת אינטרנט אחת פשוטה.
איור 3: תיאור שלבי המסגרת המוצעת במחקר בה הרובוט מזהה את ההצבעה ומשערך את המיקום וזווית ההצבעה לפי מידע שנרכש בעזרת המצלמה ובנוסף תהליך סגמנטציה על התמונה. לבסוף, הרובוט מתכנן את מסלול ההתקדמות לצורך הגעה ליעד.
במחקר אנו מציעים שיטה ייחודית המבוססת על שלושה מודלים של למידה עמוקה ושילוב של מידע הכולל תמונות והסגמנטציה שלהם. את שלבי המסגרת הכללית המוצעת בזמן אמת ניתן לראות באיור 3, כאשר תחילה אנו מקבלים רצף של תמונות, המודל המסווג מחליט האם קיימת הצבעה או לא, במקביל התמונה עוברת תהליך סגמנטציה ומשולבת כקלט למודל הזיהוי והשערוך. במידה וקיימת הצבעה, המודל שערוך מקבל כקלט את התמונה ואת הסגמנטציה שלה ומשערך את מיקום וזוויות ההצבעה. לבסוף, הרובוט מתכנן את הכיוון ליעד הרצוי על פי המידע שניתן לו (מיקום וזוויות).
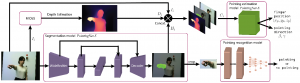
איור 4: תיאור השיטה המוצעת לצורך זיהוי האם קיימת הצבעה ושערוך של מיקום וכיוון שלה.
מודל הסגמנטציה אשר תכננו מזהה את הזרוע של המשתמש ומפלח אותה משאר התמונה במטרה להסיר את הרקע ולהשאיר רק את הזרוע של המשתמש, במהלך בחינת המודל המסווג ראינו שסיווג בעזרת תמונות אלו הוא יעיל בהרבה יותר. כדי לאמן את מודל הסגמנטציה נדרש מאיתנו לבצע תיוג ידני על התמונות, כדי לאפשר למודל להבין מה עליו לחפש. איור 4 מתאר את השיטה הייחודית אשר פיתחנו לצורך פתרון הבעיה, כאשר מתקבל תמונה בודדת היא עוברת למודל הסגמנטציה לצורך פילוח הזרוע מהמשתמש וזאת במטרה ליצור מידע אחיד נטול הפרעות של זרוע לצורך אימון המודל המסווג. במקביל, התמונה עוברת דרך מודל MiDaS ההופך תמונות צבע (RGB) לתמונות עומק. לאחר מכן, אנו מאחדים בין שלושת התמונות (רגילה, סגמנטציה ועומק) כקלט למודל המשערך. המודל משערך לנו את מיקום ההצבעה והזוויות.
במהלך השנים פותחו מודלים רבים אשר נחשבים כמודלים מתקדמים לזיהוי מחוות ולהערכת תנוחות ופוזות של האדם, אך הם מספקים דיוק נמוך של אומדן זווית ההצבעה , השיטה שאנו מציעים משיגה דיוק של פחות מ-. השיטה נבחנה בתצורות שונות ובזמן אמת, כפי שמוצג באיור 5, ניתן לראות בסצנות השונות את המשתמש מצביע לנקודה מסוימת (איקס שחור), הרובוט מזהה שקיימת הצבעה, מפלח את הזרוע של המשתמש, משערך את המיקום והזוויות של ההצבעה ולבסוף מתכנן את התנועה לעבר הנקודה המשוערכת.

איור 5: בחינת המודל בזמן אמת, כאשר הרובוט מזהה הצבעה הוא משערך את המיקום והכיוון שלה ונע לכיוון המטרה.
