Doris Chen & Deshanand Singh, Altera
דחיסה פרקטלית היא טכניקה יעילה לקידוד תמונות ווידיאו המשתמשת במושג של קודים המתייחסים לעצמם (self-referential). אם כי הן מציעות איכות דחיסה השווה או העוברת טכניקות מסורתיות בעזרת תהליך פענוח מהיר יותר ופשוט יותר, הטכניקות הפרקטליות לא השיגו הסכמה רחבה בשל האופי החישובי ביותר של אלגוריתם הקידוד שלה. במאמר זה, אנחנו מציגים מימוש בזמן-אמת של אלגוריתם לדחיסה פרקטלית ב-OpenCL []. אנחנו מראים כיצד ניתן לממש אלגוריתם זה בצורה יעילה ב-OpenCL ולייטב אותו עבור multi-CPUs, GPUs ו-FPGAs. אנחנו מוכיחים שחישוב הליבה הממומש ב-FPGA דרך OpenCL הוא מהיר פי שלושה מ-GPU מתקדם ופי 114 מהיר יותר מאשר CPU מרובה-ליבות, עם יתרונות הספק משמעותיים. אנחנו גם משווים למימוש של FPGA המקודד ידנית כדי להוכיח את היעילות של כלי קומפילציה OpenCL ל-FPGA.
רקע
שיטות ביצוע שונות קיימות כמעט בכל היישומים. חלקים אחדים של היישום יכולים להתמקד בבקרת התזרים, שם מערכי פקודות שונים מבוצעים בתלות במבוא היישום. חלקים אחרים יכולים להיות אינטנסיביים למחשוב, שם יש לעבד כמויות גדולות של נתונים עם מערך פקודות דומה. קשה ביותר לבצע את שני הקצוות של הספקטרום בצורה מיטבית בעזרת אותה החומרה. כדי להקל על האצת האלגוריתם, יישומים אלה מחולקים לעתים קרובות לשני רכיבי חומרה. רכיב אחד מבצע בקרת תזרים בחלקים כבדים של התכנון, בשעה שהחלק המקביל לנתונים מבוצע על-ידי רכיב שני. דגם יישומי זה מכונה לעתים קרובות דגם התכנות “מארח + מאיץ” בדגם זה, המארח אחראי לתזרים הבקרה, ומשיק את המאיץ כדי לבצע משימות בנתונים מקבילים. המארח, בדרך כלל מעבד לשימוש כללי (CPU) ומבצע את החלקים הטוריים של התכנון בתוכנה. למאיץ, שהוא יותר ניתן לשינויים, יש תמיכת HW יסודית עבור משימות של נתונים מקבילים. מוטל על המתכנת לבצע חלוקת HW/SW, ולקבוע איזה חלק של היישום יש להאיץ ב-HW. האתגר של דגם תכנות זה הוא חוק Amdahl, בו מהירות היישום מוגבלת על-ידי החלק הטורי של היישום.
במאמר זה, אנחנו דנים ביישום של דחיסה פרקטלית, המבוססת על התיאוריה של מערכות פונקציה חוזרת (iterated function systems – IFS). לצורכי קידוד של נתוני תמונה או וידיאו, האלגוריתם מחלק את התמונה לאזורים, ושואף למצוא משוואה ליניארית אחת אשר תתאר בצורה הטובה ביותר כל אזור. כדי לפענח את התמונה, משוואות ליניאריות אלו מופעלות בצורה החוזרת על עצמה על התמונה עד להשגת התכנסות. החלק הממוחשב ביותר של היישום הוא הקידוד; שלב הפענוח הוא לרוב מהיר מאוד. לכן, אנחנו מתמקדים בחלק הקידוד של היישום.
כדי לקודד תמונה, אנחנו יוצרים תחילה ספר קודים (codebook) המכיל נתוני ייחוס המופקים מאזורים שונים של התמונה. עבור כל אזור שיש לקודד, אנחנו מסתכלים דרך כל כניסות ספר הקודים ומוצאים את הכניסה המייצגת, לאחר הכפלת גורם קנה-מידה והיסט, בצורה הטובה ביותר את האזור המיועד. אם כן, הדחיסה מושגת מאחר שניתן לייצג כל אזור בשלושה ערכים: ID כניסה בספר הקודים התואם ביותר, גורם קנה-המידה והיסט.
על-סמך ההערכה הראשונית, החלק המחשובי ביותר הוא החיפוש אחר כניסת ספר הקודים המתאימה ביותר. יש להשוות כל אזור עם כל הכניסות בספר הקודים. לכן, חלק זה מועבר להתקן האצה בשעה ששאר היישום, כגון עיבוד המסגרת והפקת ספר הקודים, נשאר על המארח.
בעבר, נעשתה כבר עבודה מסוימת על האצת הדחיסה הפרקטלית.
המחברים מציעים מתודולוגיה של תכנון משותף חומרה/תוכנה עבור דחיסת תמונה תוך שימוש ב-FPGA. הם מראים האצה של 6x-8x לעומת התוכנה. נשקלה האצה תוך שימוש ב-GPU; אולם העבודה מוגבלת בקירוב לערך מסגרת אחת בשנייה והיא איננה קרובה כלל לזמן-אמת. עבודות אחרות, דוגמת הציגו קידוד עבור וידיאוים בעלי רזולוציה ואיכות נמוכות. מימושי ASIC גם הוצגו כמשיגי מהירויות של זמן-אמת; אולם עבודות מוקדמות אלה משתמשות לרוב בתמונות קטנות בשחור-לבן שעשויות לא להיות מייצגות. בעבודה שלנו, אנחנו מעבדים וידיאו בצבע מלא 704×576 ושואפים להגיע למהירויות של זמן-אמת (60 מסגרות בשנייה).
למטרה זו, אנחנו מעריכים שלוש פלטפורמות: ה-CPU מרובה-ליבות, ה-GPU וה-FPGA .CPUs מרובי-ליבות מכילים יחידות-עיבוד עצמאיות, או “ליבות”, המממשות מערך פקודות full-custom. כלומר, קיימת תמיכת חומרה עבור פקודות מורכבות. ליבות אלו יכולות להיות מרובות-הליכים (multi-threaded), דבר המגביר עוד יותר את המקבילות האפשרית. ל-CPUs מרובי-ליבות יכולים להיות מטמונים (cache) על-השבב בעלי גדלים שאפשר לחלקם על-ידי הליבות שלהם. אם כי ליבות או הליכים (threads) יכולים לתקשר ביניהם, הביצועים הטובים ביותר מושגים לרוב על-ידי הגבלת התקשורת הבין-פתילית ועל-ידי שימוש במערך נתוני ביצוע שיכול להתאים בקלות במטמון על-השבב.
הפלטפורמה השנייה שנאמדה היא ה-GPU .GPUs הם מעבדים מיוטבים ביותר הידועים בכוח המחשוב שלהם בפעולות גראפיות. בשעה שמעבדים לשימוש כללי מיוטבים לשם הקטנת הכמיסות (latency), ה-GPU מתוכנן כדי למקסם את תפוקת היישום. כדי להשיג זאת, GPUs מעבדים עשרות אלפים של הליכים במקביל על מערך של יחידות מחשוב. GPUs גם מספקים תמיכה בחומרה למיתוג התוכן בין קבוצות של הליכים אם מערך ההליכים השוטף מתעכב בהמתנה לגישה לזיכרון הגלובלי. דבר זה מאפשר ליחידות המחשוב לבצע עבודה מועילה ולהסתיר כמיסויות של גישה לזיכרון. דוגמה של ארכיטקטורת Fermi ב-GPU מוצגת באיור 2. אבן הבנייה של ה-GPU הוא ה-Streaming Multiprocessor (). הוא מכיל 32 יחידות מחשוב בנקודה צפה, או (Stream Processors – SP), ו-4 יחידות תפקיד מיוחדות עבור חישובים משופרים (transcendental). מאחר שקבוצות הליכים פועלות לעתים קרובות ביחד על אותו מערך נתונים, ה-SM מציג זיכרון מקומי המחולק בין ההליכים כמו גם מטמונים כך שדרושות פחות גישות לזיכרון הגלובלי. ה-GPU של Fermi ניתן לתכנות תוך שימוש אם כי ה-CUDA מכילה ספריות מיועדות ל-GPU עבור יישומים מסוימים, מחקר חדש הראה שניתן להשיג ביצועים דומים על-ידי המהדרים (compilers) הן של OpenCL והן של ה-CUDA.
קידוד פרקטלי נראה כבחירה טובה עבור ה-GPU .GPUs פועלים היטב מטבעם על נתוני תמונות; רוחב-הפס שלהם הוא ללא מתחרה של כל פלטפורמה אחרת. מאחר שהאלגוריתם פועל על אזורים עצמאיים קטנים, ה-GPU יכול להשיק בקלות אלפי הליכים עם מעט מאוד עזרה של זיכרון משותף או אוגרים (registers) מקומיים.
הפלטפורמה השלישית שהוערכה היא ה-FPGA. בעבר, לפלטפורמה זו היה מחסום גבוה בפני כניסות. אם כי ניתן להתאימה במלואה ללקוח כדי ליישם כל נתיב נתונים, כדי להאיץ יישום, יש לכתוב את חלק הקרנל של התכנון בשפת תאור חומרה כגון ה-Verilog/VHDL. על המתכנן לשים לב לרצף הנתונים בכל מחזור, ולהכיר את ארכיטקטורת ההתקן היטב כדי לנצל במלואו את היתרון של המעגל הזמין. כדי להקל על סוגיות אלו, Altera השיקה כלי הידור (compilation).
ברמה הגבוהה, ה-SDK של Altera עבור מתרגם קרנל OpenCL לחומרה על-ידי יצירת מעגל המממש כל פעולה. מעגלים אלה מחווטים יחד כדי לדמות את תזרים הנתונים בתוך הקרנל. לדוגמה, עיין בקרנל פשוט לחיבור וקטורי כמוצג באיור 3a. קרנל זה מתאר פונקציית C פשוטה בה העתקים רבים של פונקציה זו רצים תיאורטית במקביל. כל הליך מקבילי משויך ל- (get-global-id) (0) המראה את התת-מערך של נתונים שכל הליך פועל בו. התרגום לחומרה יצור את מבנה המעגל ברמה גבוהה המוצג באיור 3b. העומסים ממערכי A ו-B מומרים ליחידות עומס שהן מעגלים קטנים האחראים להפצת כתובות לזיכרון החיצוני ולעיבוד של הנתונים החוזרים. שני ערכי הנתונים החוזרים מזינים במישרין יחידת סיכום האחראית לחישוב של חיבור בנקודה צפה של שני ערכים אלה. לבסוף, תוצאת המסכם (adder) מחווטת ישירות ליחידת אכסון הכותבת את הסיכום בחזרה לזיכרון החיצוני.
הרעיון החשוב ביותר מאחורי המהדר OpenCL-to-FPGA הוא המושג של מקבילות הצנרת (pipeline parallelism). שלא כמו ב-CPUs ו-GPUs מרובי-ליבות בהם יש כבר יחידות חומרה תואמות רבות הזמינות כבר, ה-FPGA צריך להיות יותר יעיל בשימוש במשאבים הזמינים שלו. לשם פשטות, הנח שהמהדר יצר שלושה שלבי צנרת בשביל הקרנל כמתואר באיור 4. במחזור השעון הראשון, ההליך ID 0 נמדד בתוך שתי יחידות העומס. דבר זה מראה שעליהם להתחיל לתפוס את המרכיבים הראשונים של נתונים ממערכי A ו-B.
במחזור השעון השני ההליך ID1 נמדד כאשר באותו הזמן ההליך 0 השלים את הקריאה שלו מהזיכרון ואכסן את התוצאות באוגרים שלאחר יחידות העומס. במחזור 3, ההליך ID2 נמדד, ההליך 1 לוכד את הנתונים החוזרים, והליך 0 מאכסן את הסכום של שני הערכים המועמסים. ברור שבמצב קבוע, כל חלקי ההליך פעילים, כאשר כל שלב מעבד הליך שונה.
בנוסף לצנרת הקרנל, המהדר יוצר ממשקים לזיכרון החיצוני והפנימי. יחידות העומס והאכסון של כל צנרת מחוברות לזיכרון החיצוני דרך מבנה חיבורים גלובלי המתווך בין דרישות מרובות לקבוצה של DDR DIMMs. בדומה, גישות הזיכרון המקומי של ה-OpenCL מחוברות דרך מבנה חיבורים מיוחד ל-M9K RAMS על-שבב.
דחיסה פרקטלית
הדחיסה הפרקטלית מבוססת על תיאוריית המערכות בעלות הפונקציות החוזרות על עצמם (iterated function systems – IFS). המושגים מוסברים בצורה הטובה ביותר באמצעות דוגמה. דמיינו תמונה דו מימדית 2DI שהיא בגובה N פיקסלים ורוחב N פיקסלים. דבר זה ניתן להציג תוך שימוש בווקטור החד-ממדי P בעל N2 מרכיבים המסודרים בצורה הבאה:
שיטת הדחיסה מבוססת על יצירת קשר של וקטור זה על בסיס גרסא מוחלפת של אותו הווקטור. לשם הדגמה, חשבו על המקרה הטריוויאלי בו יש לנו תמונה בעלת פיקסל יחיד בעל ערך עוצמה שווה ל-4. התאורייה הפרקטלית אומרת לנו שאנחנו יכולים לבטא את תמונת הפיקסל היחיד תוך שימוש ביחס להלן:
יחס חוזר זה מכונה הקוד הפרקטלי עבור התמונה. התהליך של פענוח התמונה מהקוד הפרקטלי מבוסס על שימוש בקשר החוזר החל מערך התחלתי אקראי כלשהו כמתואר באיור 5.
הערך ההתחלתי של x נבחר ל-10. בכל צעד, אנחנו משתמשים במשוואה 2 עד שהערך של x מתכנס ל-4. ניתן להראות שללא תלות בערך ההתחלתי, המערכת תתכנס לאותו הערך. שים לב שקשר חוזר זה כרוך בהבעת ערך כגרסא בשינוי גודל של הערך בתוספת היסט קבוע. במקרה של הפיקסל היחיד, החזרה תתכנס תמיד אם גודל וקטור שינוי הגודל יהיה בהחלט פחות מ-1.
ניתן לבטא קודים פרקטליים עבור תמונות כלליות בצורה דומה למקרה של הפיקסל היחיד:
במשוואה זו, P הוא וקטור המכיל N2 ערכי פיקסל, A היא מטריצה התמרה של N2 x N2 מרכיבים ו-C הוא וקטור היסט המכיל N2 ערכים. זוהי הכללה של גורם שינוי הגודל וההיסט הקבוע הנדון במקרה של פיקסל יחיד. תהליך הפענוח משתמש בטכניקה חוזרת החל מתמונה אקראית P0:
עבור מטריצות שהן כוויציות (contractive), ניתן להראות שתהליך זה מתכנס לערך של (I-A) -.
השימוש בנוהל מוכלל כדי לתאר תמונות תוך שימוש בקודים פרקטליים נראה כחסר תועלת במונחים של דחיסה, מאחר שמטריצות ההיפוך וההיסט הן יותר גדולות מהתמונה עצמה. גורם המפתח בדחיסה הוא שאיננו זקוקים למטריצות אלו בעצמן, אלא במידע מספיק כדי לתאר אותן בשלמותן.
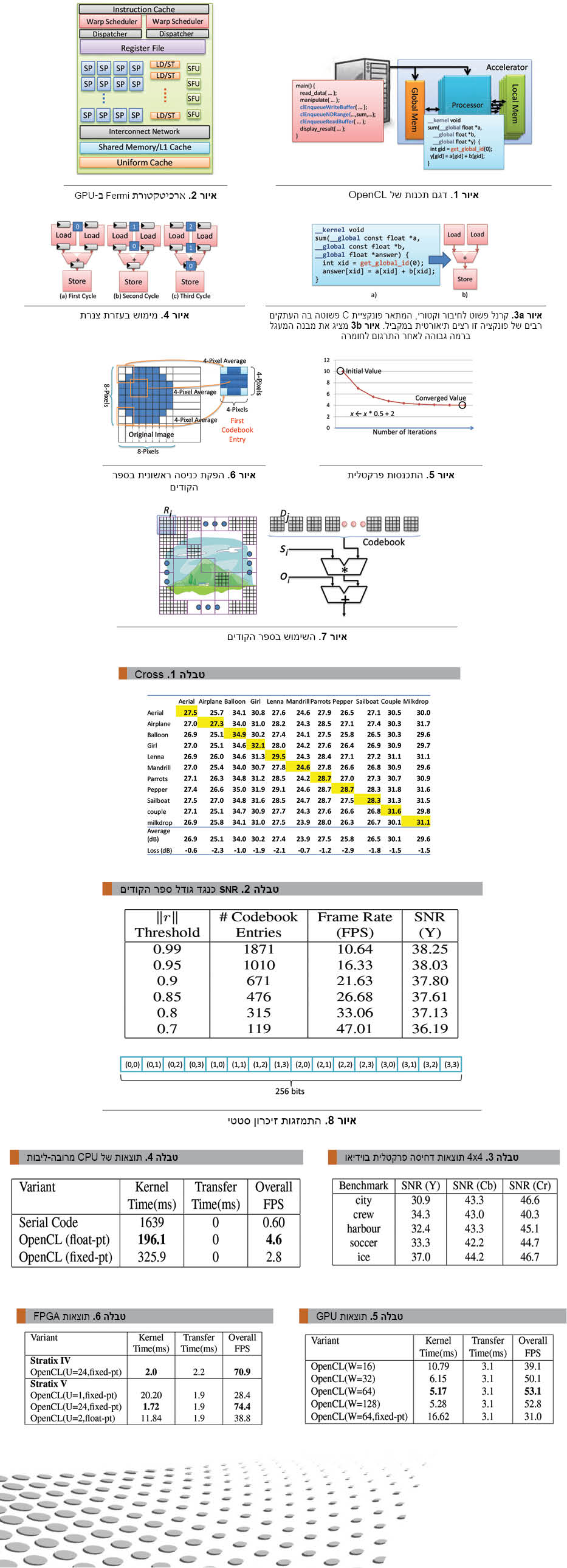
התהליך מתחיל בהפקת ספר קודים. עבור כל אזור 8×8 בתמונה המקורית אנחנו מפיקים תמונת ספר קודים 4×4 כמתואר באיור 6.
דבר זה דוחס בצורה יעילה אזור של 64 ערכי פיקסלים לתוך תמונה קטנה יותר בעלת ערכים של 16 פיקסל. ההפחתה מבוצעת על-ידי מיצוע של 4 ערכי פיקסל באזורי 2×2. בשעה שאנחנו השתמשנו בשיטה זו של הפקת ספר קודים של
8×8->4×4, ממדים וסכמות אחרים רבים הם אפשריים. תהליך זה של המרת אזורי 8×8 ל-4×4 כניסות בספר הקודים חוזר עבור כל אזור 8×8 בתמונה המקורית ויוצר ספריה של תמונות בספר הקודים. מספר התמונות בספר הקודים בספריה זו הוא (N/8) .
ספריית ספר הקודים שימושית כדי לבטא תמונה כיחס חוזר תוך שימוש במטריצות ההמרה A ו-C. חשבו על התמונה המקורית המוצגת באיור 7.
אנחנו יכולים לחלק תמונה זו
ל-(N/4) אזורי 4×4. עבור אזור מסוים Ri, הדחיסה הפרקטלית שואפת למצוא את כניסת ספר הקודים התואמת ביותר D, התואם את האזור Ri. במקום להתאים פשוט את כניסת ספר הקודים עצמה, מוכנסים גורם גודל si והיסט oi כדי למצוא התאמה עוד יותר הדוקה. בצורה יותר פורמלית, דבר זה ניתן לבטא כ- DjECodebook si,oi
חישוב זה הוא בעצם סיכום של ההפרשים המוחלטים (SAD) בין Ri והגרסה מותאמת בגודל ובהיסט של Dj, עבור כל Dj בספר הקודים. תהליך זה מבוצע עבור כל אחד מהגושים 2 Ri ומאפשר לנו להפיק משוואות דוגמת:
R0~ 0.5*D23+31
R1~0.25*D39+6
…
שים לב שהחלק השמאלי של מערכת משוואות זו מכיל ערכים עבור כל פיקסל בתמונה המקורית. החלק הימני מכיל ערכים לפי מידה של כניסות ספר הקודים. אולם, זכור שכניסות ספר הקודים עצמן נובעות מההפחתה 8×8->4×4 של התמונה המקורית. שים לב גם שערכי ההיסט יכולים להיחשב כווקטור של מספרים המתווספים לכניסות ספר הקודים לפי קנה מידה. במהות, יצרנו קוד פרקטלי מאחר שיש לנו משוואה בצורת P~AP+C.
אין צורך להעביר למעשה את המטריצה A או C. אנחנו רואים שניתן לבטא כל Ri על-ידי:
Ri=si*Dj+oi
כל Ri הוא תצוגה של 4×4 פיקסלים בתמונה המקורית. דחיסה פרקטלית מאפשרת לנו להציג אזור Ri זה בעזרת ערכי ה-j ,si ו-oi. אין צורך להעביר את כניסות ספר הקודים עצמן מאחר שהמפענח יכול להתחיל מכל תמונה אקראית ראשונית, ליצור ספר קודים מזה, להפעיל את השינויים עבור כל משוואה Ri ולחזור עד ההתכנסות. לרוב דבר זה קורה אחרי 4 עד 5 חזרות.
הדחיסה מבוצעת מאחר שאנחנו צריכים רק 3 ערכים כדי לייצג את האזור 4×4 כולו. ניתן לכמת ערכים אלה כדי לשפר עוד יותר את הדחיסה. אנחנו מציגים את סכמות הכימות הללו תוך שימוש
ב-((#Bits(j), #Bits(si), #Bits(oi)). מאחר ש-si ו-oi הם מספרים בערכים ריאליים, מספר הביטים מראה את מספר הערכים אשר שימשו. לדוגמה השימוש ב-2 ביטים עבור גורם ה-si יכול להתבצע תוך שימוש רק ב-4 גורמי קנה-מידה דיסקרטיים {-1, -0.5, 0.5, 1}. גורמי קנה-מידה אלה צריכים להיות מסונכרנים בין המקודד והמפענח ואנחנו משתמשים בכימות יחיד במאמר זה כדי לפשט זאת יותר.
לבחירת פרמטרי הדחיסה יש פשרות באיכות התמונה המפוענחת. איכות התמונה נמדדת לרוב במונחים של יחס אות לרעש בשיא
(Peak Signal-to-Noise Ratio – PSNR).
ערכי PSNR בין 27dB ו-30dB נותנים תוצאות לרוב שהן נעימות למראה. המטרה שלנו היא למצוא דחיסה גבוהה מקודים פרקטליים תוך שמירה על ערכי PSNR טובים.
מימוש קידוד פרקטלי
המימוש שלנו ב-OpenCL של קידוד פרקטלי מבצע את הצעדים הבאים:
קרא תמונה או נתוני וידיאו מקובץ והמשך לחציצת מסגרת
עבד מסגרת תמונה יחידה
צור ספר קודים
השתמש באלגוריתם חיפוש מבוסס SAD כדי למצוא את הכניסות התואמות ביותר ולהפיק קודים פרקטליים
ראשית, אנחנו דנים במימוש של עיבוד מסגרת תמונה יחידה. דבר זה מהווה הבסיס של מערכת דחיסת הוידיאו שלנו. אנחנו גם מתארים ייטובים מיוחדים ליישום המתאימים לכל הפלטפורמות שהערכנו.
דחיסת תמונה פרקטלית
במימוש שלנו, התמונה מחולקת לעד 4×4 אזורים. כניסת ספר קודים אחת מחושבת מכל אזור 8×8 של התמונה. על-ידי ביצוע ניסויי פשרה על קריטריונים אחדים, קבענו שהשימוש ב-7 גורמי קנה-מידה, נותן תוצאות המובילות ליחסי PSNR טובים מבלי להתפשר על יחסי הדחיסה. כניסות מדודות אלו מתווספות לספר הקודים הגלובלי ומאפשרות לנו לבצע את שינוי הגודל רק פעם אחת.
המימוש הראשון של המקודד ב-C++ הראה ש-99.8% מזמן הדחיסה כרוך בחישוב של כניסה בספר הקודים הטובה ביותר תוך שימוש ב-SAD. לכן, הורדנו חישוב זה אל מאיץ. ספר הקודים עדיין מחושב על המעבד המארח x86, אך הוא נשלח למאיץ עם נתוני התמונה לשם חישוב. אנחנו יוצרים קרנל בעל נתונים מקבילים גבוה המחזיר את הכניסה Dj התואמת ביותר, גורם השינוי si והיסט oi.
כדי לזרז את החיפוש בספר הקודים, אנחנו משיקים נושא-עבודה או הליך אחד לכל אזור 4×4 כדי לחשב תחילה את הסכום של ההפרש המוחלט של מיקומי ה-16 פיקסל. היתרון בהשקת הליך אחד לכל אזור 4×4 הוא בכך שכל הליך הוא עצמאי; אין צורך בזיכרון משותף.
דחיסת וידיאו פרקטלית
כדי ליישם קידוד פרקטלי לוידיאו, אנחנו קודם קוראים את נתוני הוידיאו בפורמט YUY2 ומעבירים אותו לחוצצי מסגרת. כל מסגרת מכילה מישורי Y ,Cr ו-Cb המעובדים לפי הסדר. האסטרטגיה הכללית שלנו עבור דחיסת וידיאו כוללת קידוד של מסגרות חדשות תוך שימוש בספר הקודים של המסגרת המקורית. כדי להדגים מושג זה, אנחנו מבצעים ניסוי cross-coding תוך שימוש בקריטריוני עיבוד תמונה סטנדרטי, שם אנחנו משתמשים בספר הקודים של תמונה אחת כדי לקודד תמונה שונה. בטבלה 1, התמונה הנמצאת בראש הרשימה היא מקודדת עם ספר הקודים של התמונה הרשום בעמודה השמאלית.
מניסוי זה אנחנו רואים שההפסד הממוצע ב-PSNR הוא רק 1dB; יכולים לבטא תמונות מאוד שונות בעזרת ספרי קודים מתמונות שונות. למשל, תמונה של בחורה בוטאה בקלות תוך שימוש בספר הקודים מתמונה של תוכים.
ניסוי זה מדריך את הגישה הכללית שלנו. המסגרת הראשונה עוברת עיבוד תמונה פרקטלי כמתואר בפרק A. נתונים דחוסים אלה מועברים למפענח שם המסגרת הראשונה משוחזרת. ממסגרת זו, המפענח יכול לשחזר העתק של ספר הקודים של המקודד כך שלמקודד ולמפענח יהיו ספרי קודים מסונכרנים.
עבור מסגרות הוידיאו הבאות, אנחנו מחפשים אזורי 4×4 ששונו בהשוואה למסגרת הראשונית. עבור כל אזור שעבר שינוי, אנחנו מנהלים את הסקר הטוב ביותר של כניסות בספר הקודים עם ספר הקודים מהמסגרת הראשונה; אנחנו שולחים לאחר מכן את כניסת ספר הקודים אל המפענח כדי להציג את האזור 4×4 לאחר השינוי. מאחר שלמפענח יש ספר קודים משוחזר מהמסגרת הראשונה, קל מאוד לזהות את ההחלפה עבור אזור 4×4 שעבר שינוי.
ייטוב ספר הקודים
כדי להשיג מהירויות דחיסה בזמן-אמת, אנחנו רואים שזמן הריצה של הקרנל מושפע ישירות מגודל ספר הקודים. יל-ידי בחינה של היישום, מתברר מיד שניתן להקטין את ספר הקודים המועבר לקרנל. ספר קודים זה מכיל 7 גרסאות בקנה-מידה של כל כניסה לספר קודים המחושבת מהתמונה. ייטוב פשוט הוא לשמור על כניסת ספר קודים אחת בלבד. על המאיץ, הפתיל המקומי לחבר את שבעת גורמי המידה לכל כניסה לפני חישוב ה-SAD. על-ידי כך, אנחנו יכולים להאיץ את זמן המעבר של ספר הקודים פי 7x. הקרנל מוחלף בהתאם לכך עם לולאה נוספת החוזרת 7 פעמים, פעם אחת בכל גורם מידה. זמן הריצה הכולל של הקרנל נשאר ללא שינוי. הקוד המדומה עבור קרנל זה מוצג להלן:
kernel void compute f r a c t a l c o d e (
short* currImage , short* codeBook , . . . ) {
short myImage [ 1 6 ] , c e n t r y [ 1 6 ] ;
/ / computing the average
i n t average = 0;
i n t imageOffset = g e t g l o b a l i d (0) * 16;
for ( each p i x e l i in r e g i o n ) { / / loop i s u n r o l l e d
short va l = currImage [ imageOffse t+ i ] ;
average += val ;
myImage [ i ] = v a l ; }
average >>= 4; / / d i v i d e by 16 to get average
for ( each p i x e l in r e g i o n ) / / loop i s u n r o l l e d
myImage [ i ] *= average ;
u s h o r t b e s t s a d = 16 * 256 * 2 ;
i n t bestCodebookEntry = *1, b e s t S c a l e = *1;
for ( each codebook ent ry icode ) {
for ( i =0; i <16; i ++) / / loop i s u n r o l l e d
c e n t r y [ i ] = codeBook [ icode *16+ i ] ;
for ( each s c a l e f a c t o r sFac ) {
u s h o r t sad = 0;
for ( i =0; i <16; i ++) / / loop i s u n r o l l e d
sad += abs ( sFac * c e n t r y [ i ] * myImage [ i ] ) ;
i f ( sad < b e s t s a d ) {
b e s t s a d = sad ;
bestCodebookEnt ry = icode ;
b e s t S c a l e = sFac ;
אם כי קני המידה מוצגים כנקודה צפה, אין הדבר נחוץ מאחר שלערכים אלה יש ייצוג מדויק בנקודה קבועה. יתר על כן, ניתן להפעיל את קנה המידה באמצעות הזזת ביטים וחיבורים, במקום להשתמש במכפלה. לדוגמה, קנה המידה של 0.75 שווה-ערך ל-:
דבר זה מפשט את האריתמטיקה החיונית לשם הפעלת קני-מידה.
אנחנו גם רושמים שעשויה להיות יתירות משמעותית בכניסות לספר הקודים. כדי להקטין עוד יותר את מספר הכניסות לספר הקודים, אנחנו מחשבים את מקדם הקורלציה r, המוגדר במשוואה 9, בין הכניסה השוטפת והכניסות הסמוכות לה.
כאשר n הוא מספר הכניסות בווקטורי x ו-y. אם r נמצא מעל סף מסוים, אזי אנחנו מחשיבים את הכניסה שחושבה לאחרונה להיות דומה לשכנתה, ולכן יתירה, ולא מתווספת לספר הקודים. אנחנו מכוונים לאחר מכן את הסף כדי להבטיח שה-SNR איננו מופחת משמעותית. טבלה II מראה את הפשרה של PSNR וקצב הקידוד עבור מערך הניסוי שלנו כאשר הסף וההיסט מופחתים.
ייטוב הגישה לזיכרון
כאשר פיקסלים ממוקמים במיקומים עוקבים, ניתן לאפשר גישה רחבה יעילה לזיכרון במקום דרישות יותר קטנות מרובות. דרישות יותר גדולות רציפות שואפות לאפשר יעילות גבוהה יותר כאשר הן מתקשרות לחוצצים הממוקמים ב-SDRAM שמחוץ לשבב.
כדי להקטין את מספר דרישות הזיכרון הנחוצות, אנחנו אירגנו מחדש את נתוני התמונה וספר הקודים כך שכל אזור 4×4 הוא רציף בזיכרון. דבר זה מוצג באיור 8. דבר זה אינו גורם לעלות בזמן הריצה על המארח, אך אנחנו מסוגלים להקטין את מספר דרישות העומס פי 4. דבר זה מבטיח שאנחנו משתמשים בזיכרון החיצוני הזמין בצורה יעילה עבור כל פלטפורמה.
תוצאות
לשם ביצוע השוואות פלטפורמות, מימשנו דחיסה פרקטלית תוך שימוש ב-3 פלטפורמות HPC מבטיחות: CPU מרובה-ליבות, GPU ו-FPGA. המעבד Intel Xeon W3690 משמש להערכת פלטפורמת CPU מרובת-הליבות. מעבד איכותי זה מכיל 6 ליבות הרצות ב-3.46 גיגה-הרץ, ועוד hyper-threading. נציגת ה-GPU שנבחרה היא ה-NVIDIA C2075 Fermi GPU. עבור מימוש ה-FPGA, השתמשנו בכרטיס Nallatech PCIE385N-a7 עם FPGA Stratix V 5SGXA7 מאחר שזוהי טכנולוגיית ה-FPGA החדשה ביותר בעת הכתיבה. אולם, מאחר והיא נמצאת בתהליך יותר חדש, אנחנו כוללים גם מימוש ב-Terasic DE4 עם FPGA Stratix IV 530 לשם השוואה. פרטים על הפלטפורמות שנבחרו מוצגים בטבלה III. קיימים מספר הבדלי יסוד בפלטפורמות החומרה הנדונות. קיים הבדל ברור בצריכת ההספק מאחר שה-FPGA צורך 21-25 ואט בעוד CPU ו-GPU מדורגים כ-130 ו-215 ואט בהתאמה. צוין שבעוד הספק ה-GPU וה-FPGA כולל את צריכת ההספק של הזיכרון הראשי, הספק ה-CPU מרובה-הליבות אינו כולל אותו. שנית, ל-GPU
ול-CPU יש יתרונות משמעותיים ברוחב-הפס של הזיכרון החיצוני. ל-GPU יש פי 5.6 עד 11 יותר רוחב-פס של הזיכרון החיצוני מאשר ל-FPGAs. בעוד המעבד מרובה-הליבות ניתן להשוואה, השימוש של הבזק על-השבב של 12 מגה-בייט מאפשר גישה לנתוני רוחב-פס מאוד גבוה בתוך מערך העבודה של היישום.
הפקת נתונים ניסיוניים
בהתחשב בייטובים המתוארים בפרק IV, יצרנו מימוש OpenCL המבוטא בפרמטרים שניתן לכוון לפלטפורמות מרובות. השתמשנו במערך פתוח לציבור של רצפי וידיאו שהם צבעונים במלואם ובעלי רזולוציה של 704×576. כל הפלטפורמות הממומשות יוצרות תוצאות זהות פונקציונלית; זמן הקידוד משתנה בתלות במאפייני הפלטפורמה. טבלה IV מראה את תוצאות ה-SNR של הרצת רצפי וידיאו אלה דרך האלגוריתם של דחיסה פרקטלית שלנו. עבור כל ניסוי,SNRs מעל 30dB בקביעות מצביעים על תוצאה בעלת איכות גבוהה. כל התוצאות מבוטאות תוך שימוש בסף קורלציה של 0.8.
יחס הדחיסה
עבור כל אזור 4×4 המכיל 8 ביטים לפיקסל, התמונה המקורית דורשת 128 ביטים. הקודים הפרקטליים דורשים 25 ביטים בהתחשב ב-IDs כניסה בספר הקודים
שלנו, קנה המידה והיסטים. אולם, עבור רוב המסגרות אנחנו משדרים deltas המראים על השינוי בקודים הפרקטליים הללו תוך התקדמות הוידיאו. מאחר שהשינויים בוידיאו הטיפוסיים בין מסגרות אינם פתאומיים, ה-deltas הללו הם קטנים. קידוד-Huffman יכול לעבד לאחר מכן את מקדמי הקודים הפרקטליים ולהוביל ליחס דחיסה של כ-9.7x עבור מישור ה-Y. מאחר שלמישורי Cr ו-Cb יש ערכי PSNR הרבה יותר גבוהים, יכולנו להמיר בקלות איכות PSNR כלשהי לטובת יחס דחיסה עוד יותר גבוה. יש גם שינויים מרובים בקודים הפרקטליים כגון subsampling שיכולים לסייע להשיג אפילו יחסי דחיסה עוד יותר גבוהים ללא כל השפעה על אלגוריתם קרנל הליבה.
תוצאות CPU מרובה-ליבות
אופציית המימוש הראשונה שנחקרה הייתה ה-CPU מרובה-ליבות. המימוש OpenCL שלנו של דחיסת וידיאו פרקטלית הורצה על CPU Xeon W3690 באמצעות השימוש ב-SDK OpenCL של [20]. התוצאות שלנו מוצגות בטבלה V. אנחנו מראים שלוש גרסאות שונות של המימוש ומדידת הביצועים של זמן הביצוע של הקרנל, זמן המעבר בין קרנל ומארח ואת ביצועי היישום הכוללים במסגרות לשנייה (frames per second – FPS).
כל נתון מדידה של ביצועים בטבלה מייצג את הביצועים הממוצעים למשך חמשת ניסויי הוידיאו שנדונו קודם לכן.
הגרסה הראשונה שנחקרה היא אלגוריתם רצף מובהק עבור התכנית הן של הקרנל והן של המארח. דבר זה משמש כקו ייחוס כאשר לא משתמשים במקבילות מפורשת. הזמן הממוצע שנלקח על-ידי קרנל הדחיסה הפרקטלית הוא 1.6 שניות למסגרת. מאחר שאנחנו מבצעים קרנלים OpenCL על אותו התקן כמו תכנית המארח של ה-OpenCL, אין עונשין עיליים עבור מעברי נתונים. הביצועים של מימוש רציף בהחלט זה מוגבלים לכ-0.6FPS.
הגרסא השנייה שנחקרה הייתה מימוש של OpenCL המשיק הליכים מקבילים עבור כל אזור 4×4. גרסה זו השתמשה גם בחישוב של נקודה צפה כדי להעריך את הכניסות המדודות של ספר הקודים. במקרה זה, זמן הקרנל מקוצר כמעט פי 8 עד 196 מילי-שניות. כפי שנדון מקודם, היישום הכללי מורכב מעיבוד רציף כלשהו על המארח ביחד עם אלגוריתם הדחיסה המקביל ביותר. מהירות היישום תהיה תמיד מוגבלת על-ידי קטע רציף זה. תוצאת ה-FPS במקרה זה שופרה ל-4.6FPS.
לצורכי השוואה, מימשנו את קוד ה-OpenCL בנקודה קבועה תוך שימוש בפעולות של מספרים שלמים והזזות ביטים. דבר זה היה יותר איטי בצורה מפתיעה מאשר תוצאת ה-CPU בנקודה צפה. שיערנו שדבר זה נגרם בשל החישובים בנקודה קבועה הדורשים לבטא מספר גדול של פקודות פשוטות. למעבד יש חומרה מיוחדת לשם תמיכה בנקודה צפה כך שעשוי להיות רווח קטן מהמרת החישוב לרצף של פעולות פשוטות רבות.
תוצאות GPU
בהמשך הפעלנו את מימוש ה-OpenCL על מערכת GPU. במערכת זו המעבד המארח היה שוב W3690 של Xeon, והקרנל OpenCL הופעל על GPU NVIDIA Fermi C2075 בעזרת השימוש ב-SDK OpenCL של . התוצאות מוצגות בטבלה VI. כמתואר בפרק II, GPUs מורכבים משורה של מרכיבי עיבוד ודורשים לרוב לחלק את הבעיה לתוך תת-בעיות קטנות יותר הרצות על כל רב-מעבד תזרימי. דבר זה מבוקר תוך שימוש במושג של קבוצת-עבודה (workgroup) שהיא פשוט קבוצת הליכים המשתפים פעולה כדי לפתור תת-בעיה. לצורכי דחיסת וידיאו פרקטלית, אנחנו מחלקים את ההליך המקבילי לקבוצות של W הליכים. בטבלה VI, אנחנו מוצאים שכאשר W גדול מ-64, זמן הריצה נשאר יחסית קבוע. זמן הקרנל הוא בערך 5.2 מילי-שניות ומהווה שיפור פי 40 מונים לעומת המימוש של CPU מקבילי.
במקרה זה יש גם תקורת זמן מעבר של 3.1 מילי-שניות לשם העברת הנתונים הלוך ושוב בין המעבד המארח וה-GPU. בגין שיפור זה, הביצועים הכוללים של המימוש עולים עד 53FPS.
בדומה להערכת ה-CPU, המימוש OpenCL בנקודה צפה הטוב ביותר מוחלף בחישובי נקודה קבועה שווי-ערך. שוב, מגמה דומה ניתן לראות כאשר זמן הקרנל הוא בערך 3 פעמים גרוע יותר מאשר יישום הנקודה הצפה. בהתחשב ש-GPUs מומחים במיוחד בנקודה צפה, תוצאה זו עקבית עם מימושי הנקודה הקבועה ודורשת יותר פקודות עבור אותו חישוב.
תוצאות FPGA
הפלטפורמה האחרונה אשר הוערכה היא מערכת מבוססת-FPGA המורכבת ממעבד מארח Xeon W3690 ביחד עם כרטיס Terasic DE4 עם FPGA Syratix IV 530 או כרטיס מאיץ Nallatech PCIE385n עם התקן Stratix V 5SGXA7. הקרנל OpenCL ממופה להתקן ה-FPGA תוך שימוש ב-SDK של Altera עבורOpenCL. ניתן לראות בנקל את העצמה של כלי OpenCL ל-FPGA בתוך הניסויים שלנו; שינוי המטרה של המימוש ל-Stratix V מ-Stratix IV נעשה בקלות על-ידי שינוי בחירת הכרטיס של המהדר. התוצאות מוצגות בטבלה VII. כמוסבר מקודם, ה-FPGA משתמש במושג של מקבילות צינור עיבוד הנתונים כדי להשיג האצה כאשר ההליכים מתקדמים דרך יחידות פונקציונליות מקבילות רבות. ה-FPGA יכול להשיג יותר מהירות כאשר יש לו יותר יחידות כאלו נוכחות על ההתקן. המתכנת יכול לבקר את כמות הלוגיקה תוך שימוש בטכניקות דוגמת גילול הלולאה (loop unrolling). טבלה VII מראה את התוצאות עבור כמה גורמי גילול לולאות, U, עבור הלולאה החיצונית ביותר החוזרת דרך עניבות של ספר הקודים. גורם גילול של 2 יצביע על כך של-FPGA יש די חומרה כדי להעריך 2 כניסות של ספר קודים למחזור. תוך שימוש בחישובי נקודה קבועה וגורם גילול של 24, אנחנו משיגים זמן קרנל של 2 מילי-שניות על Stratix IV עם קצב יישום כולל של 70.9FPS.
על Stratix V, אנו משיגים זמן קרנל של 1.72 מילי-שניות עם קצב יישום כולל של 74.4FPS. המימוש של Stratix V הוא יותר מהיר ב-16% בזמן קרנל מאשר המימוש של Stratix IV. פער זה צפוי לגדול מאחר שמתקן ה-Stratix V ששימש במחקר זה הוא רק FPGA בעל מידות בינוניות במשפחת ההתקנים שלו, בעוד ה-Stratix IV 530 הוא הגדול ביותר במשפחת ההתקנים של 40 מ”מ. השימוש בחישוב נקודה קבועה מספק תוצאות זהות למקרה של הנקודה הצפה עם חומרה הרבה יותר פשוטה; פעולות דוגמת הזזת ביטים הצורכות פקודות על המעבד הופכות למוליכים פשוטים על ה-FPGA ללא כל עונשין.
מצאנו שכאשר השתמשנו בחישוב בנקודה צפה, כמות הגילולים האפשרית הייתה מוגבלת מאחר שליבות הנקודה הצפה הן הרבה יותר גדולות מאשר המקבילות שלהן בנקודה קבועה. גורם גילול של 2 יצר זמן קרנל של 11.8 מילי-שניות וקצב מימוש של 38.8FPS.
עלינו לציין שתי נקודות מעניינות. ראשית, כאשר אנחנו עוברים מגורם גילול 1 ל-24, אין האצה ליניארית של x24 בזמן הקרנל. גורם עיקרי אחד המגביל את ההאצה הוא שאלגוריתם דחיסת הוידיאו מחשב רק מקדמים פרקטליים עבור אזורי 4×4 ששונו. עבור מסגרות אחדות, מספר זה הוא די קטן, וגורם לצינור נתוני FPGA פחות מנוצל. בנוסף, שמנו לב שתדר הפעולה המרבי של מעגלי ה-FPGA מופחת במעט כאשר ההתקן הופך ליותר מלא. שנית, מצאנו שזמן המעבר של ה-FPGA הוא מהיר יותר בכ-1 מילי-שנייה מאשר ה-GPU. דבר זה היה בלתי-צפוי. השגנו שהדבר נגרם בשל ההבדלים במימוש הדרייבר. המימוש שלנו מבצע הרבה מעברים קטנים; ה-GPU אולי איננו מיוטב עבור תרחיש שימוש זה.
נקודת השוואה מעניינת עבור תוצאת ה-FPGA הוא להשוות למימוש מקודד ידני הכתוב ב-Verilog. איור 9 מראה מימוש מקודד ידני עבור חלקי הליבה של האלגוריתם. בשל המורכבויות של תכנון מקודד ידני, בחרנו לשמור על חציץ המסגרת וספר הקודים מאוכסנים במלואם בזיכרון על-שבב. הארכיטקטורה שלנו כוללת העמסת גוש Ri יחיד לתוך קבוצת אוגרים המכילה את כל ערכי ה-16 פיקסלים. באופן דומה, אנחנו חוזרים דרך כל כניסה בספר הקודים המאוכסנת ב-RAM על-השבב ומורידים כל כניסה בספר הקודים Dj בתוך אוגר מקבילי. הערך של Dj מכוון על-ידי יחידת נקודה קבועה המותאמת עבור גורם קנה-מידה מסוים. גוש זה מכיל רק הזזות ותוספות עבור גורמי קנה-המידה המשמשים במאמר זה. ניתן להכפיל את נתיב הנתונים המלא 7 פעמים כדי לטפל ב-7 גורמי קנה-המידה המשמשים במימוש ה-OpenCL. מאחר שאנחנו זקוקים לזיכרון מספיק כדי לשמור את כל ספר הקודים בזיכרון על-השבב, אנחנו לא יכולים להשוות ישירות את תוצאות מימוש RTL זה לצינור הנתונים המופק אוטומטית OpenCL. ה-SDK של Altera עבור OpenCL מאפשר לנו לגלל את הלולאה החיצונית ביותר 24 פעמים כך ש-24 הכניסות בספר הקודים (בעלות 7 גורמי קנה-מידה כל אחד) ניתנות להערכה בכל מחזור שעון. הגרסה המקודדת ידנית מוגבלת ל-4 חזרות מגוללות.
מימוש ה-RTL שלנו הוא מוגבל בזיכרון בשל השימוש הבלעדי ב-RAM על-שבב. לכן הביצועים שלו הם פי 6 יותר נמוכים מאשר מימוש ה-OpenCL שלנו מאחר שכל משאבי הזיכרון אזלו אחרי גילול פי 4. אם כי המימוש המקודד ידנית שלנו היה יותר פשוט מאשר מימוש ה-OpenCL, ההבדל בזמן הפיתוח היה משמעותי. גרסה מקודדת ידנית זו ארכה חודש אחד לשם השלמה, בשעה שה-SDK ב-OpenCL היה מסוגל ליצור אוטומטית תכנון FPGA פועל תוך שעות.
סיכום
במאמר זה, הוכחנו כיצד ניתן לתאר קידוד פרקטלי תוך שימוש ב-OpenCL ופירטנו את הייטוב הנחוץ כדי למפות אותו ביעילות בכל פלטפורמה. הראנו שחישוב הליבה על-ידי קרנל הוא 3 פעמים מהיר יותר מאשר GPU איכותי תוך צריכה של 12% מההספק. אנחנו גם פי 114 מהירים יותר מאשר CPU מרובה-ליבות, תוך צריכה של 19% מההספק. המחקר שלנו היה מוגבל על-ידי טכנולוגיית GPU ו-FPGA שעמדה לרשותנו בשעת הכתיבה. NVIDIA הכריזה על GPU Kepler חדש המציע פי שניים ביצועים מאשר ה-GPU Fermi מהדור הקודם. בדומה, השתמשנו בהתקן Stratix V 5SGXA7 במחקר זה; התקנים יותר גדולים ב-50% יהיו זמינים בקרוב.
זרימת התכנון של OpenCL היא די פשוטה להבנה ויוצרת מימוש שהוא זהה כמעט למימוש בקידוד ידני. למעשה, זרימת ה-OpenCL מטפלת אוטומטית במורכבויות רבות של הממשק החיצוני כגון DDR ו-PCIe שלא נוסו אפילו עבור הגרסה המקודדת ידנית.
אם כי מימוש ה-FPGA הוא שלוש פעמים יותר מהיר מאשר ה-GPU, קצב המסגרות הנוצר שופר רק ב-40%. הסיבה היא שזמן הקרנל של FPGA וזמן העברת הנתונים הוא רק 27% מזמן הריצה למסגרת. כדי לשפר עוד יותר את זמן הריצה של היישום, עבודתנו העתידית כוללת הורדה של יותר חישובים למאיץ, כגון הפקת ספר הקודים.
הכתבה נמסרה באדיבות חברת איסטרוניקס מפיצת Altera בישראל