















עומסי העבודה של היסקים ביישומי בינה מלאכותית וארכיטקטורות המחשוב הדרושות לתמיכה בהם מתפתחים במהירות. הם גם נעשים יותר ויותר מגוונים בדרכים בלתי צפויות. לחוסר חיזוי זה יש השפעה משמעותית על הדיוק, הביצועים והיעילות של ההיסקים.
הפתרון המידי הוא להקצות יותר משאבי מחשוב על מנת לפתור את הבעיה – מעבדים רבים יותר והתקני זיכרון מהירים וטובים יותר. עם זאת, גישה זו מספקת תשואות פוחתות, גם אם התקציב אינו מוגבל ומאפשר פריסה של טכנולוגיות כגון זיכרון ברוחב פס גבוה (HBM) ועיבוד בזיכרון.(PIM – Processing In Memory) במקום זאת, צצות חלופות ממוקדות ומותאמות יותר, כולל מאיצים ייעודיים, השונות מארכיטקטורות מחשוב מסורתיות. ישנן מספר ארכיטקטורות האצה המתחרות על מנת לשרת בצורה הטובה ביותר את עומסי העבודה של בינה מלאכותית, אך “מחשוב בזיכרון” בבסיסו הוא הארכיטקטורה הטובה ביותר לא רק לעומסי העבודה הנוכחיים של בינה מלאכותית, אלא גם לאלה של המחר, הגם כשהם ממשיכים להתפתח ולהתפצל בדרכים בלתי צפויות.
עומסי העבודה של היסקים בבינה מלאכותית מתרבים ונעשים יותר מגוונים
היסקים ביישמי בינה מלאכותית משתרעים על שימושים רבים בתעשיות שונות. חלקם די פשוטים וניתן למצוא אותם בטלפונים חכמים בשימוש יום יומי על ידי רוב האנשים. עם זאת, אלה שמאתגרים את ארכיטקטורות המחשוב המסורתיות הן אלו המטפלות בכמויות גדולות של נתונים בתעשיות שבהן יש לקבל החלטות מהירות כדי לתמוך בהצלחת התוצאות העסקיות, באמינות הציוד ואפילו בבטיחות תפקודית.
הקיפי עסקאות גדולים הם מסימני ההיכר של תעשיית השירותים הפיננסיים. אך בינה מלאכותית מציבה אתגרי עיבוד נתונים חדשים למגזר זה כיוון שהוא מחפש למנף עיבוד שפה טבעית (NLP) כדי לחלץ נתונים ממסמכים מובנים ובלתי מובנים כאחד.
תת-תחום של בלשנות, מדעי המחשב ובינה מלאכותית, NLP מאפשר לבנקים לבצע אוטומציה ואופטימיזציה של משימות כמו חיפוש מסמכים ואיסוף מידע על לקוחות. זה גם מסייע להם להעריך בצורה יעילה יותר את התהליכים שמאיצים את הביצועים העסקיים, ולבנות תחזיות טובות יותר של השווקים על ידי הערכת מגוון נתוני טקסט ודיבור מהקשרים שונים.
בינה מלאכותית נמצאת בשימוש גם ברצפת הייצור בתעשיות שונות – ומבצעת באמצעות למידה עמוקה אוטומציה של תהליכים בתחומים רבים, כולל בשרשרת אספקה, פיתוח מוצרים וייצורם. במקרים מסוימים, בינה מלאכותית בשירות התעשייה ממנפת נתונים מהאינטרנט של הדברים (IoT) וממכשירי קצה אחרים. ככל שהחומרה של הבינה המלאכותית, וטכנולוגיות המוליכים למחצה מתפתחות ומשתפרות, טכנולוגיה זו חודרת יותר ויותר ליישומים תעשייתיים, ומאיצה את תהליך הפריסה של ציוד אוטונומי ברצפות הייצור.
באופן דומה, היסקי בינה מלאכותית ממלאים תפקיד מפתח בכלי הרכב המודרניים (בין אם הם אוטונומיים לחלוטין ובין אם לאו) ובמערכות תחבורה באופן רחב יותר. היכולת של בינה מלאכותית לעבד ולחזות נתונים מאפשרת תזמון יעיל ואמין של תחבורה פרטית וציבורית. במכונית עצמה, היסקים מדויקים הם קריטיים באופן בו כלי רכב יפרשו את הסביבה שלהם וכדי להבטיח נווט בטוח בהתבסס על תמרורי תנועה, התנהגות של נהגים אחרים ומכשולים בלתי צפויים על הכביש. כל המגוון הזה של עומסי העבודה של בינה מלאכותית מוביל לארכיטקטורות רשתות עצביות מגוונות עוד יותר. ההתפתחות המהירה, פיצול עומסי העבודה הללו ופיתוח ארכיטקטורות חדשות מקשים עוד יותר על אפשרויות החיזוי, ומדגיש עוד יותר את האתגרים הקיימים העומדים בפני היסקי בינה מלאכותית, ויוצרים אתגרים חדשים.
המכשולים העומדים בפני היסקי בינה מלאכותית
התעשיות העושות שימוש בבינה מלאכותית הינן רבות ומגוונות. כפי שהוכיחו תעשיות כמו שירותים פיננסיים, רצפות ייצור ומכוניות, האתגר הוא להפוך אותן למעשיות מבחינה טכנולוגית, וגם אז, הטכנולוגיה צריכה להיות חסכונית וניתנת להרחבה.
אלגוריתמים המרכיבים למידה עמוקה ולמידת מכונה הם עתירי כוח מחשוב, ולכן הפתרון הברור לאתגרי היסקי בינה מלאכותית הוא מינוף מחשוב בעל ביצועים גבוהים באמצעות המעבדים החזקים ביותר וזיכרונות DRAM העדכניים והטובים ביותר, ואף HBM. אולם, אפילו עם הזמינות של משאבי מחשוב לפי דרישה דרך הענן, המערכות המתקדמות יותר הדרושות להיסקים עשויות להיות יקרות מאוד. וגם אם העלויות הגבוהות אינן המכשול, הוספת כוח מחשוב על ידי GPUs ומעבדים אינה תמיד הפתרון הטוב ביותר.
למעבד אכן יש תפקיד בעומסי עבודה של בינה מלאכותית; הוא מתאים במיוחד עבור אלגוריתמים ומשימות עוקבות הדורשות לקיחת פיסת נתונים קטנה יחסית ולשנות אותה בשלבים עוקבים. דוגמאות לכך מהעולם האמיתי כוללות זיהוי תמונה ומיקום סימולטני ומיפוי עבור כלי רכב אוטונומיים ומזל”טים, או מכשירים ביתיים עם פונקציות NLP פשוטות. עם זאת, בעוד שמעבדים לא יכולים לעמוד בדרישות ביצועים ויעילות, רשתות עצביות מודרניות הן יקרות מאוד.
בינתיים, GPUs עברו כברת דרך ארוכה מהשורשים שלהם במשחקים במחשבים אישיים, ובעיקר כאמצעי לטיפול בעיבודי תצוגה גרפיים. הם מתאימים היטב לעומסי עבודה של בינה מלאכותית שיכולים לעשות שימוש בעיבוד מקבילי מסיבי שהם מציעים. עם זאת, ה-GPUs מציבים אתגרים רבים. הם צרכנים גדולים מאוד של הספק, ואם משאבי הזיכרון אינם תואמים את משימות העיבוד – זמן ההשהיה יתארך.
הוספת זיכרון עשויה להגדיל את תפוקת המערכת הכוללת, אך ישנן מגבלות גם בגישה זו. ההתפשטות והגיוון של עומסי העבודה בבינה מלאכותית האיצה את ההתפתחות של מפרטי זיכרונות DRAM (של DDR ו-LPDDR) והובילה להתעניינות גוברת ב- HBM, כמו גם
ב-PIM. DRAM נשאר הזיכרון המהיר ביותר וסביר להניח שגרסאות דלות הספק של DRAM יאומצו לפתרונות קצה מבוססות היסקים ביישומי בינה מלאכותית, כמו גם ביישומי אוטומוטיב. HBM עודנו זיכרון הפרמיום, כש-PIM עדיין בתחילת דרכו, מאחר ורק בזכות הפיתוחים האחרונים מתאפשרת אינטגרציה שלו ללא שינויים משמעותיים בתוכנה. יש להשקיע עבודה רבה נוספת על מנת ש- PIM יהיה בשימוש מסחרי נרחב.
האתגרים שמציבים עומסי עבודה בבינה מלאכותית, הכוללים נפחים הולכים וגדלים של נתונים, הובילו לפיתוח של מאיצים ייעודיים המביאים את הנתונים למקום בו הם צריכים להיות, תוך כדי הפחתת הצורך בהעברת נתונים בין המעבדים, הזיכרון והאחסון. מחשוב הטרוגני, שבו המערכת יכולה לגשת בקלות לתמהיל הנכון של מחשוב, זיכרון ואחסון עבור עומס עבודה נתון, כמו גם הופעתו של מפרט Compute Express Link (CXL) המאפשר גישה למאגרים נפרדים של זיכרון, מעוררים עניין רב כאמצעי לטיפול בצווארי הבקבוק הפוגעים בעומסי העבודה של בינה מלאכותית.
בינתיים, ניתן לצפות שלא תהיה הפוגה באתגרים העומדים בפני פריסות מוצלחות של היסקי בינה מלאכותיות, וישפיעו על הדיוק, הביצועים והיעילות. שינוי עומסי העבודה של בינה מלאכותית מובילים לארכיטקטורות מגוונות יותר של רשתות עצביות, וארכיטקטורות אלו יתפתחו בעתיד בדרכים שעדיין לא ידועות. המטרה היא לוודא שאלגוריתם יכול לפעול בהצלחה על ארכיטקטורת הרשת שנבחרה. שמירה על דיוק היא גם אתגר, שכן קוונטיזציה עמוקה יכולה להוביל לאובדן דיוק וטכניקות אנלוגיות עלולות להיסחף.
גם אם הדיוק נשמר, הביצועים עלולים להתדרדר אם הארכיטקטורה לא יכולה להשיג יעדי תפוקה והשהייה. גם אם הדיוק נשמר, הביצועים עלולים להתדרדר אם הארכיטקטורה לא יכולה להשיג יעדי תפוקה והשהייה. מקסום מספר התמונות והשאילתות לשנייה וכן מזעור נפחי מאגרי הזיכרון, תוך השגת יעדים אלו הם מדד הצלחה מרכזי לעומסי עבודה של בינה מלאכותית. מיקסום תמונות ושאילתות לשנייה וכן מזעור גדלי אצווה תוך השגת יעדים אלו הוא מדד הצלחה מרכזי לעומסי עבודה של בינה מלאכותית. מאידך, אין להשיג יעדי ביצוע תוך פגיעה ביעילות. בתורו, אין להשיג יעדי ביצוע תוך פגיעה ביעילות. הארכיטקטורה הנבחרת חייבת לקבל את הביצועים האופטימליים מהסיליקון תוך איזון צריכת ההספק. דרוש ביצוע אופטימיזציה של תמונות ושאילתות פר שנייה פר וואט תוך התחשבות בכל עלויות להקמת המערכת, כמו גם עלות הבעלות הכוללת שלה.
בעוד שארכיטקטורת in-memory עשויה להיות הבחירה הטבעית מנקודת מבט טכנולוגית, מחשוב at-memory נותן היום מענה לאתגר הספציפי העומד בפני פריסות בינה מלאכותית.
מחשוב At-Memory הוא הפתרון להאצת ביצועי בינה מלאכותית
שלא כמו הארכיטקטורות הנפוצות כיום של near-memory ו- von Neumann, התלויות באפיקים ארוכים וצרים ובמטמונים עמוקים ו/או משותפים, ארכיטקטורת מחשוב בזיכרון משתמשת בחיבורים מקבילים ישירים , תוך שימוש בזיכרון ייעודי וליעילות ורוחב פס רחב.
ארכיטקטורת von Neumann מסורתית תהיה ככל הנראה בעלת DRAM חיצוני, מטמון וערוץ גישה לרכיבי עיבוד, בעוד שלגישת מחשוב בזיכרון יש את רכיבי העיבוד מחוברים ישירות לתאי הזיכרון.
Untether AI בחרה להשתמש ב- SRAM בארכיטקטורת המחשוב בזיכרון, אבל זה חלק קטן מהסיפור. לא רק שיש ל- Untether AI רכיבי עיבוד המחוברים ישירות לתאי SRAM , אלא שהם כוללים מעבד RISC ו-512 יחידות עיבוד נוספות, כשלכל אחד מהם מחובר למערך SRAM משלו. כל מעבד RISC מתוכנן בהתאמה כדי להאיץ רשתות עצביות.
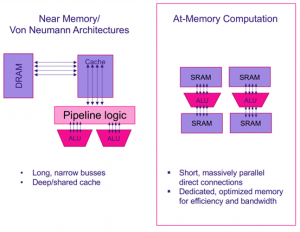
תמונה 1 :מחשוב Memory-At וארכיטקטורות מחשוב מסורתיות
קרדיט: UNTETEHR AI
על ידי הצבת הרשת העצבית כולה על-שבב, Untether AI מספקת השהיה נמוכה ותפוקה גבוהה בו זמנית. היכולת של Untether AI להניע את התפוקה נובעת מהקצאה פיזית – מיקום ‘השכן-קרוב’ מקטין את צריכת ההספק ומפחית את זמן ההשהיה, בעוד הניתוב והמחשוב מאוזנים כדי לייעל את התפוקה הכוללת. פונקציות העלות מוכוונות לפרמטרים של חומרה. לעומת זאת, ארכיטקטורת von Neumann משתמשת ב CPU- או ב- GPU שחייבים להחליף שכבות ומקדמים מהזיכרון תוך כדי קיבוץ הנתונים בקבוצות גדולות יותר כדי לסייע בתפוקה, וכתוצאה מכך, זמן ההשהיה מושפע לרעה.
ארכיטקטורת המחשוב בזיכרון של Untether AI מייצגת את גישת “הטוב משני העולמות” בכך שהיא משלבת פקודות מרובות, נתונים מרובים (MIMD) והוראה בודדת, ריבוי נתונים MIMD . (SIMD) מאפשר אופטימיזציה מרחבית עם 511 מאגרי זיכרון הפועלים באופן אסינכרוני, בעוד שאופטימיזציה רציפה מושגת באמצעותSIMD , עם 512 יחידות העיבוד לכל בנק זיכרון מתבצעות בהוראה אחת.
ארכיטקטורת המחשוב בזיכרון של Untether AI מותאמת לעומסי עבודה בקנה מידה גדול ומספקת השהיה נמוכה מאוד שארכיטקטורות near-memory או von Neumann לא מסוגלות לספק. על ידי שימוש ביחידות אריתמטיות של מספרים שלמים בלבד, ניתן להגדיל את התפוקה תוך הפחתת העלות. הגמישות נשמרת על מנת לספק תמיכה רחבה למגוון רחב של רשתות עצביות עבור היסקי בינה מלאכותית המבוססת על NLP , רשתות עצביות מוכוונות ראייה ומערכות במגזרי תעשייה מגוונים, כולל ראייה תעשייתית, פיננסים, קמעונאות חכמה ורכבים אוטונומיים ועוד יישומים רבים אחרים, מנוע מחשוב הבינה מלאכותית של Untether AI מציעה שני מנועי מחשוב מבוססי חומרה לבינה מלאכותית.
- משפחת מעבדי הבינה המלאכותית runAI200 להאצת היסקים תוך שימוש בנתוני מספרים שלמים וארכיטקטורת at-memory הייחודית של Untether AI המספקת 502 tera פעולות בשנייה, ויעילות של 8 TOPS/W.
- מעבדים אלה משובצים בכרטיס ההאצה tsunAImi, המספקים 2 peta פעולות מחשוב בשנייה בכרטיס בודד. עבור עיבוד שפה טבעית, הכרטיס יכול לעבד 12,000 שאילתות לשנייה (לפי BURT-base).
אבל החומרה לבדה אינה מספיקה כדי לפרוס בהצלחה עומסי עבודה של בינה מלאכותית.
Untether AI מציעה את ערכת הפיתוח imAIgine התואמת למסגרות העבודה המוכרות של למידת מכונה הכוללת TensorFlow ו- PyTorch עם אינטגרציית Jupyter Notebook.
השילוב של מחשוב מבוסס at-memory עם ערכת פיתח התוכנה מציע ביצועים גבוהים וצריכת הספק נמוכה בהיסקי בינה מלכותית, על פני מגוון רחב של רשתות, וגמישות עבור ארכיטקטורת רשת עצבית עכשיוית , וצופה את חוסר החיזוי של העומסים העתידים של בינה מלאכותית.
לפרטים נוספים: אבנר אוזן, 5408863-050
il.co.easx@uzan.a
