















המערכות פיקוח ומעקב (surveillance) מסתמכות במידה רבה מאוד על היכולת המוקנית להן על ידי מערכות ראייה משובצות, שמאפשרת את פרישתן בטווח רחב של שווקים ויישומים. מערכות פיקוח ומעקב אלו משמשות במספר רב של יישומים, החל בניטור אירועים ותעבורה, יישומי בטיחות ואבטחה ועד יישומי ISR (מודיעין, מעקב ואיסוף מידע) ואיסוף מידע עסקי. מבחר זה גורם לכמה אתגרים מניעים שלהם צריכים לתת מענה מתכנני המערכות בפתרון שהם מציעים. האתגרים הם:
ראייה באמצעות מצלמות מרובות – יכולת להתחבר בממשק אל סוגי חיישנים רבים, הומוגניים או הטרוגניים.
טכניקות של ראייה ממוחשבת – יכולת פיתוח באמצעות ספריות ומסגרות עבודה ברמה גבוהה כגון OpenCV ו- OpenVX.
טכניקות של למידת מכונה – יכולת להשתמש במסגרות עבודה כגון Caffe על מנת לממש מנוע הסקת מסקנות (inference engine) בלמידת מכונה.
רזולוציות וקצבי מסגרות שגדלים והולכים – מגדילים את עיבוד הנתונים הנדרש עבור כל מסגרת של תמונה.
בתלות ביישום, במערכות הפיקוח והמעקב ימומשו אלגוריתמים כמו למשל זרימה אופטית (optical flow), כדי לגלות תנועה בתוך התמונה. ראייה בסטריאו מספקת תפישה תלת ממדית בתוך התמונה, בעוד טכניקות של לימוד מכונה משמשות גם כדי לגלות ולסווג עצמים בתוך התמונה.
התקני מערכות על שבב הטרוגניים לתכנות מלא, כמו למשל מערכות על שבב בריבוי מעבדים Zync®–7000 ו-™Zync® UltraScale +, משמשים יותר ויותר לפיתוח של יישומי פיקוח ומעקב. התקנים אלו משלבים ליבות ®ARM בעלות ביצועים גבוהים שיוצרות מערכת עיבוד (PS) עם מארג (fabric) לוגיקה ניתנת לתכנות (PL).
הצימוד ההדוק בין מערכת העיבוד לבין הלוגיקה הניתנת לתכנות מאפשרת יצירה של מערכת יותר מגיבה, שניתנת להגדרת קונפיגורציה והיא בעלת נצילות גבוהה בהשוואה למערכות בגישה המסורתית. לגישות מסורתיות מבוססות יחידות יע”מ (CPU) עם יחידת עיבוד גרפי (GPU) יש צורך בזיכרון מערכת, כדי להעביר תמונות מדרגת העיבוד לדרגה הבאה. מצב זה מקטין את הדטרמיניזם, מגדיל את פיזור ההספק ומאריך את משך זמן תגובת המערכת מאחר שמשאבים רבים אמורים לגשת אל אותו זיכרון, ויוצרים בכך צוואר בקבוק באלגוריתם העיבוד. צוואר בקבוק זה גדל ככל שגדלים קצב המסגרות והרזולוציה.
המימוש באמצעות התקני המערכות SoC בריבוי מעבדים 7000 ו- מאפשר לסלק את צוואר הבקבוק הזה. התקנים אלו מאפשרים למתכנן לממש את צינור עיבוד הנתונים (pipeline) לעיבוד תמונה בתוך לוגיקת PL של ההתקן, יצירה של צינור עיבוד נתונים מקבילי אמיתי בתוך הלוגיקה כאשר המוצא של דרגה אחת מועבר למבוא של דרגה אחרת. כך מתאפשר זמן תגובה דטרמיניסטי עם פתרון אופטימלי מבחינת זמן האחזור (latency) וצריכת ההספק.
השימוש בלוגיקה ניתנת לתכנות כדי לממש צינור עיבוד נתונים לעיבוד תמונה מאפשר גם יכולת התחברות בממשק, שהיא נרחבת יותר מאשר גישות מסורתיות של מערכות CPU / GPU על שבב שקיימות עם ממשקים קבועים. האופי הגמיש של מבני כניסות ויציאות (IO) בלוגיקה ניתנת לתכנות מאפשר קישוריות מכל דבר לכל דבר, ומאפשר שימוש בממשקים בתקנים תעשייתיים, כמו למשל MIPI, Camera Link, HDMI וכיו”ב. האופי הגמיש שלהם מאפשר גם לממש ממשקים מסורתיים מן המוכן עם יכולת לשדרג אותם כך שיתמכו בתקני הממשקים המעודכנים ביותר. השימוש בלוגיקת PL מאפשר גם למערכת יכולת להתחבר בממשק עם מצלמות רבות במקביל.
מכל מקום, יש חשיבות עליונה ליכולת לממש את אלגוריתמי היישום ללא צורך בכתיבה מחדש של כל האלגוריתמים של הרמה הגבוהה בשפת תיאור חומרה (Hardware description language) כמו Verilog או VHDL. זה המקום reVISION™ Stack נכנסת לתמונה.
reV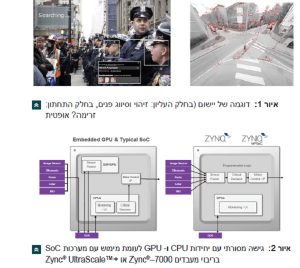 ISION Stack
ISION Stack
reVISION Stack מאפשרת לאנשי פיתוח לממש טכניקות של ראייה ממוחשבת ולימוד מכונה. פעולות אלו אפשריות בשימוש באותן מסגרות עבודה וספריות ברמה גבוהה עם המערכות על שבב בריבוי מעבדים Zync®–7000 ו- . על מנת לאפשר את השימוש הזה, reVISION משלבת טווח רחב של משאבים ומאפשרת פיתוח של פלטפורמה, יישום ואלגוריתם. ככזו, המחסנית נערכת לשלוש רמות מוגדרות:
- פיתוח הפלטפורמה – זו הרמה הנמוכה ביותר של המחסנית, אשר עליה נבנות השכבות האחרות של המחסנית. ככזו היא מספקת את הגדרת החומרה עבור הכלי ™SDSoC.
- פיתוח האלגוריתם – השכבה האמצעית של המחסנית אשר מספקת תמיכה במימוש האלגוריתם הנדרש. שכבה זו מספקת גם האצה עבור מנוע עיבוד התמונה וגם עבור מנוע הסקת מסקנות (inference engine) בלמידת מכונה בתוך הלוגיקה הניתנת לתכנות.
- פיתוח היישום – הרמה הגבוהה ביותר של המחסנית מספקת תמיכה עבור מסגרות עבודה בתקנים תעשייתיים. מסגרות אלו מאפשרות את הפיתוח של היישום אשר ממנף את שכבת פיתוח הפלטפורמה ושכבת פיתוח האלגוריתם.
רמת האלגוריתם וגם רמת היישום של המחסנית מתוכננות לתמוך בזרימת עיבוד תמונה בגישה המסורתית וגם ברצף של לימוד מכונה. בתוך שכבת האלגוריתם יש תמיכה בפיתוח של אלגוריתמי עיבוד תמונה באמצעות ספריית OpenCV. תמיכה זו כוללת את היכולת להאיץ בתוך הלוגיקה הניתנת לתכנות את פעולתן של פונקציות OpenCV במספר משמעותי (לרבות קבוצת המשנה של ליבת OpenVX). כדי לתמוך בלימוד מכונה, שכבת פיתוח האלגוריתמים מספקת כמה פונקציות חומרה שמוגדרות מראש שאותן אפשר להציב בתוך לוגיקת PL על מנת לממש מנוע הסקת מסקנות ללימוד מכונה. משכבת פיתוח היישום מתבצעת גישה אל האלגוריתמים האלו לעיבוד תמונה ואל מנועי הסקת המסקנות ללימוד מכונה על מנת ליצור את היישום הסופי ולספק תמיכה עבור מסגרות עבודה ברמה גבוהה כדוגמת OpenVX ו- Caffe.
היכולת המתאפשרת על ידי reVISION Stack מספקת את כל החלקים הדרושים כדי לממש את האלגוריתמים עבור מערכות פיקוח ומעקב בעלות ביצועים גבוהים.
האצת OpenCV בתוך reVISION
אחד ההיבטים המעניינים ביותר של שכבת פיתוח האלגוריתמים הוא היכולת להאיץ טווח רחב של פונקציות OpenCV בתוך שכבת הפיתוח של האלגוריתמים. בתוך שכבה זו, יש אפשרות לחבר בקבוצות את פונקציות OpenCV שאותן אפשר להאיץ אל תוך אחת מבין ארבע קטגוריות ברמה גבוהה:
- חישובים – קטגוריה זו כוללת פונקציות כגון הפרש מוחלט בין שתי מסגרות, פעולות ברמת הפיקסלים (חיבור, חיסור וכפל), פעולות על גרדייאנטים ועל אינטגרלים.
- עיבוד קלט – קטגוריה שמספקת תמיכה בהמרות של עומק סיביות, פעולות על ערוצים, השוואה (equalisation) של היסטוגרמות, מיפוי חוזר ושינוי גודל.
- סינון – קטגוריה שמספקת תמיכה בטווח רחב של מסננים לרבות Sobel, קונבולוציה בהתאמה אישית ומסננים גאוסייאניים.
- אחרים – קטגוריה שמספקת טווח רחב של פונקציות, בהן נכללות גילוי שפה עם Canny/ Fast/ Harris, יצירת ערכי סף ומסווגי (classifier) SVM ו- HoG.
פונקציות אלו יוצרות גם את פונקציות הליבה של קבוצת המשנה של OpenVX ומספקות אינטגרציה הדוקה עם התמיכה של שכבת פיתוח היישומים ב-OpenVX. צוות הפיתוח יכול להשתמש בפונקציות אלו כדי ליצור צינור עיבוד נתונים אלגוריתמי בתוך הלוגיקה הניתנת לתכנות. היכולת לממש פונקציות בתוך הלוגיקה בצורה כזו מגדילה באופן משמעותי את הביצועים של מימוש האלגוריתם.

לימוד מכונה ב- reVISION
reVISION מספקת אינטגרציה עם Caffe ועמה את היכולת לממש מנועי הסקת המסקנות ללימוד מכונה. אינטגרציה זו עם Caffe מתבצעת בשכבת פיתוח האלגוריתמים וגם בשכבת פיתוח היישומים. מסגרת העבודה Caffe מספקת לאנשי הפיתוח ספריות, מודלים ומשקולות רבים עבור לימוד-מקדמי בתוך ספריית C++, עם כריכות (binding) עבור ™Python ועבור ™MATLAB. מסגרת עבודה זו מאפשרת למשתמש ליצור רשתות וללמד אותן לבצע את פעולות הרצויות מבלי שיהיה עליו להתחיל מהתחלה. על מנת לעזור במחזור, משתמשי Caffe יכולים לשתף את המודלים שלהם דרך המודל Model Zoo, אשר מספק כמה מודלים של רשתות שאותם אפשר לממש ולעדכן עבור משימה מתמחה אם נדרש. רשתות ומשקולות אלו מוגדרות בתוך קובץ prototxt ובעת הפרישה בתוך סביבת לימוד המכונה, זה הקובץ המשמש להגדרה של מנוע הסקת המסקנות.
reVISION מספקת אינטגרציה עם Caffe וכך המימוש של מנועי הסקת המסקנות הופך להיות קל כמו גם לספק קובץ prototxt. מסגרת העבודה מטפלת בכל השאר. קובץ prototxt זה משמש לאחר מכן כדי לקבוע את הקונפיגורציה של מערכת העיבוד ושל הספריות המותאמות באופטימיזציה בחומרה בתוך הלוגיקה הניתנת לתכנות. הלוגיקה הניתנת לתכנות משמשת כדי לממש את מנוע הסקת המסקנות ומכילה פונקציות כמו למשל Conv, ReLu, Pooling ועוד.
מערכות ייצוג המספרים המשמשות במימושים של מנוע הסקת המסקנות ללימוד מכונה ממלאים תפקיד משמעותי גם בביצועים שלו. יישומים של לימוד מכונה משתמשים יותר ויותר במערכות מספרים בנקודה קבועה בדיוק מופחת, שהן היעילות יותר, כדוגמת ייצוג INT8. בשימוש במערכות מספרים בנקודה קבועה בדיוק מופחת אין איבוד משמעותי של דיוק בהשוואה לגישה המסורתית של שימוש בנקודה צפה (FP32). מאחר שביצוע פעולות מתמטיות בנקודה קבועה גם קל יותר באופן משמעותי מאשר בנקודה צפה, המעבר לשימוש ב- INT8 מאפשר פתרונות יעילים יותר ומהירים יותר בחלק מהמימושים. שימוש זה במערכת מספרים בנקודה קבועה מתאים במיוחד עבור מימושים בתוך פתרון של לוגיקה ניתנת לתכנות ו- reVISION מספקת יכולת לעבוד בייצוגי INT8 בתוך לוגיקת PL. ייצוגי INT8 אלו מאפשרים להשתמש בבלוקים ייעודיים של עיבוד DSP בתוך הלוגיקה הניתנת לתכנות. הארכיטקטורה של בלוקי עיבוד DSP מאפשרת לבצע בו זמנית עד שתי פעולות Multiply-Accumulate (כפל והכנסה לצובר) בעת השימוש באותן משקולות גרעין (kernel). כך מתאפשר לא רק מימוש בביצועים גבוהים, אלא גם מימוש שמספק פיזור הספק מופחת. האופי הגמיש של הלוגיקה הניתנת לתכנות מאפשר גם לממש בקלות מערכות נוספות של ייצוג מספרים בנקודה קבועה בדיוק מופחת עם אימוצם.

מסקנות
reVISION מספקת לאנשי הפיתוח אפשרות למנף את היכולת המסופקת על ידי התקני המערכות SoC בריבוי מעבדים Zync®-7000 ו-+™Zync® UltraScale. עובדה זו נכונה במיוחד מאחר שאין צורך להיות מומחה על מנת לממש את האלגוריתמים באמצעות לוגיקה ניתנת לתכנות. אפשר לממש את האלגוריתמים ויישומי לימוד המכונה האלו באמצעות מסגרות עבודה ברמה גבוהה בתקן תעשייתי, ולקצר את זמן הפיתוח של המערכת. כך מתאפשר לאיש הפיתוח למסור מערכת שמספקת יכולת תגובה מורחבת, ניתנת להגדרת קונפיגורציה ומציגה פתרון מיטבי מבחינת ההספק.
